Todo en una sola página
Content from Antes de comenzar
Última actualización: 2023-02-07 | Mejora esta página
¿Qué es Python?
Hoja de ruta
Preguntas
- ¿Qué es Python y por qué debería aprenderlo?
Objetivos
- Describir el propósito del editor, consola, ayuda, el panel explorador de variables y el panel explorador de archivos de Spyder.
- Organizar los archivos y directorios para un conjunto de análisis como proyecto de Python, y entender el propósito del directorio de trabajo.
- Saber donde buscar ayuda.
- Demostrar como proporcionar suficiente información para solucionar problemas junto con la comunidad de usuarios de Python.
Python es un lenguaje de programación de tipo general que soporta un desarrollo rápido de aplicaciones de análisis de datos. La palabra “Python” es usada para referirse tanto al lenguaje de programación, como a la herramienta que ejecuta los scripts escritos en el lenguaje “Python”.
Sus principales ventajas son:
- Es gratis
- De código abierto
- Disponible para todas las plataformas más importantes (macOS, Linux, Windows)
- Es mantenido por la Python Software Foundation
- Soporta múltiples paradigmas de programación
- Tiene una gran comunidad
- Tiene un rico ecosistema de paquetes de terceros
Entonces, ¿por qué necesitas Python para el análisis de datos?
Fácil de aprender
Python es más fácil de aprender que otros lenguajes de programación. Esto es importante debido a que al tener barreras de aprendizaje más bajas es más fácil para los nuevos miembros de la comunidad ponerse al día.
Reproducibilidad
La reproducibilidad es la habilidad de obtener los mismos resultados usando los mismos datos y análisis.
Un análisis de datos escrito en un script de Python puede ser reproducido en cualquier plataforma. Es más, si recolectas más datos o corriges datos existentes, ¡puedes volver a ejecutar los análisis de manera rápida y sencilla!
Cada vez más revistas científicas y agencias de financiación esperan que los análisis sean reproducibles, por lo tanto, saber Python te dará una ventaja sobre estos requisitos.
Versatilidad
Python es un lenguaje versátil que se integra con varias aplicaciones existentes para permitir hacer cosas sorprendentes. Por ejemplo, uno puede usar Python para generar manuscritos, de tal forma que si necesitas actualizar tus datos, procedimientos de análisis, o cambiar algo más, puedes volver a generar todas las figuras rápidamente y tu manuscrito se actualizará automáticamente.
Python puede leer archivos de texto, conectarse a bases de datos, y a muchos otros formatos de datos, ya sea en tu computadora o en la web.
Interdisciplinario y extensible
Python provee un marco de trabajo que permite que cualquier persona combine enfoques de diferentes disciplinas de investigación (y no solo de investigación) para ajustarse mejor a tus necesidades de análisis.
Python tiene una comunidad grande y amable
Miles de personas usan Python diariamente. Muchos de ellos están dispuestos a ayudarte a través de listas de correo y sitios web, tales como Stack Overflow y el portal de la comunidad de Anaconda.
Conociendo a Anaconda
La distribución de Python Anaconda incluye montones de paquetes populares como la consola Ipython, Jupyter Notebook, y Spyder IDE. Échale un vistazo al Navegador Anaconda. Puedes ejecutar programas desde el Navegador o usar la línea de comando.
Jupyter Notebook es una aplicación web de código abierto que permite crear y compartir documentos que permiten crear de manera sencilla documentos que combinan código, gráficos y texto narrativo.
Spyder es un Entorno de Desarrollo Integrado (IDE por sus siglas en inglés) que permiten escribir scripts de Python e interactuar con el software de Python desde una interfaz única.
Anaconda también viene con un gestor de paquetes llamado conda, el cual hace que sea fácil instalar y actualizar paquetes adicionales.
Proyecto de Investigación: Buenas Prácticas
Es una buena idea guardar los grupos de datos relacionados, análisis, y texto en una única carpeta. Por lo tanto, todos los scripts y archivos de texto dentro de esta carpeta pueden usar paths relativos hacia los archivos de datos. Trabajar de esta manera hace que sea mucho más fácil mover tu proyecto y compartirlo con otras personas.
Organizando tu directorio de trabajo
Usar una estructura de carpetas de forma consistente a través de tus proyectos te ayudará a mantener las cosas organizadas, y hará que sea fácil encontrar/archivar cosas en el futuro. Esto puede ser especialmente útil cuando tienes múltiples proyectos. En general, podrías llegar a querer crear directorios separados para tus scripts, datos, y documentos.
data/: Usa esta carpeta para guardar tus datos crudos. Por el bien de la transparencia y procedencia, siempre deberías guardar una copia de tus datos crudos. Si necesitas limpiar tus datos, hazlo de manera programática (i.e., con scripts) y asegúrate de separar los datos limpios de los crudos. Por ejemplo, puedes guardar los datos crudos en./data/raw/y los limpios en./data/clean/.documents/: Usa esta carpeta para guardar esquemas, borradores, y otro texto.scripts/: Usa esta carpeta para guardar tus scripts (de Python) para limpieza de datos, análisis y generación de gráficos que uses en este proyecto en particular.
Puede que tengas que crear directorios adicionales dependiendo de las
necesidades de tu proyecto, pero los que nombramos deberían ser el eje
del directorio. Para este workshop, vamos a necesitar una carpeta
data/ para almacenar nuestros datos crudos, y luego vamos a
tener que crear la carpeta data_output/ cuando aprendamos
como exportar datos como archivos CSV.
¿Qué es Programación y Codificación?
Programación es el proceso de escribir “programas” que una computadora pueda ejecutar produciendo algún resultado (útil). La programación es un proceso de múltiples pasos que implican:
- Identificar los aspectos de un problema de la vida real que pueda ser resuelto computacionalmente.
- Identificar la (mejor) solución computacional.
- Implementar la solución en un lenguaje de programación específico.
- Testear, validar, y ajustar la solución implementada.
Mientras que “Programar” se refiere a todos los pasos nombrados, “Codificación” se refiere solo al paso 3: “Implementar la solución en un lenguaje de programación específico”.
Si trabajas con Jupyter notebook:
Puedes tipear código de Python en una celda de código y luego ejecutarla presionando Shift+Enter.
El output se imprimirá directamente bajo la celda de input. Se puede
reconocer a una celda de código mediante el In[ ]: al
principio de la celda y a una celda de output por el
Out[ ]:.
Presionar el botón + en la barra de menú agregará una nueva celda.
Todos tus comandos tal como los outputs serán guardados con el notebook.
Si trabajas con Spyder:
Puedes usar tanto la consola o un archivo de script (archivos de texto plano que contienen tu código). El panel de consola (el panel abajo a la derecha, en Spyder) es el lugar donde los comandos escritos en el lenguaje de programación Python pueden ser tipeados y ejecutados inmediatamente por la computadora. También es donde se mostrarán los resultados. Puedes ejecutar los comandos directamente en la consola presionando Enter, pero serán “perdidos” cuando cierres la sesión. Spyder usa la consola IPython por defecto.
Debido a que queremos que nuestro código y flujo de trabajo sea reproducible, es mejor tipear los comandos en el editor de scripts, y guardarlos como un script. De esta manera, hay un registro completo de lo que hicimos, y cualquiera (¡incluyendo nuestros yo futuros!) pueden reproducir los resultados en su computadora de forma sencilla.
Spyder permite ejecutar comandos directamente desde el editor de scripts usando los botones de ejecución en la parte superior.
Para ejectuar el script entero haz clic en Run file o presiona F5. Para ejecutar la línea actual haz clic en Run selection or current line o presiona F9, otros botones de ejecución permiten ejecutar celdas de scripts o activar el modo debug. Cuando se usa F9, el comando en la línea actual del script (indicada por el cursor) o todos los comandos en el actual texto seleccionado serán enviados a la consola y ejecutados.
En algún punto en tu análisis podrías llegar a desear comprobar el contenido de una variable o la estructura de un objeto, sin necesariamente guardar un registro en tu script. Puedes tipear estos comandos y ejecutarlos directamente en la consola. Spyder provee los atajos Ctrl+Shift+E y Ctrl+Shift+I que te permitirán “saltar” entre el panel de scripts y el de la consola.
Si Python está listo para aceptar comandos, la consola IPython
muestra un aviso In [..]: con el número de línea actual en
la consola entre corchetes []. Si recibe un comando
(mediante tipeo, copiando y pegando o enviado desde el editor de
scripts) Python lo va a ejecutar, mostrar los resultados en la celda
Out [..]:, y luego volver con un nuevo aviso
In [..]: a la espera de nuevos comandos.
Si Python todavía está esperando a que ingreses mas datos debido a
que todavía no has terminado, la consola mostrará un aviso
...:. Significa que no has terminado de ingresar un comando
completo.
Esto es debido a que no has tipeado un paréntesis de cierre
(), ], o }) o comillas. Cuando
sucede esto, y pensaste que habías terminado de tipear tu comando, haz
clic dentro de la ventana de la consola y presiona Esc; esto
cancelará el comando incompleto y te retornará al aviso
In [..]:.
¿Cómo aprender más luego del taller?
El material que cubrimos durante este taller te dará una prueba inicial de cómo puede usarse Python para analizar datos de tu propia investigación. Sin embargo, todavía necesitarás aprender más sobre operaciones más avanzadas tal como la limpieza de tu dataset, usar métodos estadísticos, o crear gráficos bonitos. La mejor manera de hacerse competente y eficiente en Python, así como con cualquier otra herramienta, es empleándola para abordar tus propias preguntas de investigación. Como principiante, puede sentirse desalentador tener que escribir un script desde el inicio, y dado que muchas personas comparten su código en la web, modificar código existente para adaptarlo a tus propósitos puede hacer que comenzar sea más fácil.
Buscando ayuda
- revisa el menú Ayuda
- tipea
help() - tipea
?objectohelp(object)para obtener información sobre un objeto - Documentación de Python
Finalmente, una búsqueda genérica en Google o internet de “Python tarea_a_buscar” usualmente te enviará a la documentación del módulo apropiado o a un foro dónde alguien más ya ha hecho la misma pregunta.
Estoy atorada… tengo un mensaje de error que no entiendo. Empieza por googlear el mensaje de error. Sin embargo, esto no siempre funciona muy bien debido a que a veces, los desarrolladores emplean los mensajes de error provistos por Python. Por ello terminas con mensajes de error genéricos que podrían no llegar a ser de ayuda para diagnosticar un problema (Ej.: “subscript out of bounds”). Si el mensaje es muy genérico, quizás deberías incluir en tu consulta el nombre de la función o paquete que estés usando.
Sin embargo, deberías chequear Stack Overflow. Buscar usando la etiqueta [python]. La mayoría de las preguntas ya han sido respondidas, el desafío es usar la combinación de palabras apropiadas en la búsqueda para encontrar las respuestas: http://stackoverflow.com/questions/tagged/python.
Pidiendo ayuda
La clave para recibir ayuda de alguien es que ellos entiendan rápidamente tu problema. Deberías hacer que sea lo más fácil posible identificar dónde podría estar el inconveniente.
Trata de usar las palabras correctas para describir el problema. Por ejemplo, un paquete no es lo mismo que una biblioteca. La mayoría de las personas entenderán lo que quieres decir, pero otras tienen fuertes sentimientos sobre la diferencia en el significado. El punto clave es que puede hacer que las cosas sean confusas para las personas que tratan de ayudarte. Trata de ser tan precisa como sea posible cuando describes tu problema.
Si es posible, trata de resumir lo que no funciona en un ejemplo simple y reproducible. Si puedes reproducir el problema usando una pequeña cantidad de datos en lugar de tus 50.000 filas y 10.000 columnas, proporciona el dataset pequeño con la descripción de tu problema. Cuando sea apropiado, trata de generalizar lo que estas haciendo, así incluso las personas que no están familiarizadas con tu campo de estudio podrán entender tu pregunta. Por ejemplo, en lugar de usar un subconjunto de tu datase real, crea uno pequeño (3 columnas, 5 filas) y genérico.
¿Dónde pedir ayuda?
- A la persona sentada junto a tu durante el taller. No dudes en hablar con tu vecina durante el taller, compara tus respuestas, pide ayuda. También podrías estar interesada en organizar reuniones regularmente luego del taller para seguir aprendiendo una de otra.
- Tus amigables colegas: si conoces a alguien con mas experiencia que tu, ellas podrían estar capacitadas y dispuestas a ayudarte.
- Stack Overflow: si tu pregunta no ha sido contestada con anterioridad y además está bien planteada, hay chances de que obtengas una respuesta en 5 minutos. Recuerda seguir los lineamientos de cómo preguntar correctamente.
- Listas de correo de Python
Más recursos
PyPI - the Python Package Index
The Hitchhiker’s Guide to Python
- Python es un lenguaje de programación de código libre y plataforma independiente.
- SciPy es un ecosistema para Python que provee las herramientas necesarias para la computación científica.
- Jupyter Notebook y la Spyder IDE son excelentes herramientas para escribir código e interactuar con Python. Con su gran comunidad es fácil encontrar ayuda en internet.
Content from Breve introducción a la Programación en Python
Última actualización: 2023-02-07 | Mejora esta página
Intérprete
Hoja de ruta
Preguntas
- ¿Qué es Python?
- ¿Porqué deberías aprender Python?
Objetivos
- Describir las ventajas de usar programación vs. completar tareas repetitivas a mano.
- Definir los tipos de datos en Python: cadenas, enteros, y números de punto flotante.
- Realizar operaciones matemáticas en Python utilizando operadores básicos.
- Dentro del contexto de Python definir: listas, tuplas, y diccionarios.
Python es un lenguaje interpretado que puede ser usado de dos formas:
- Modo “Interactivo”: cuando lo usas como una “calculadora avanzada”
ejecutando un comando a la vez. Para iniciar Python en este modo,
simplemente ejecuta
pythonen la línea de comandos:
SALIDA
Python 3.5.1 (default, Oct 23 2015, 18:05:06)
[GCC 4.8.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>Los res símbolos de mayor que >>> forman un
indicador interactivo en Python, que significa que está esperando tu
entrada de datos.
SALIDA
4SALIDA
Hello World- Modo “Script”: cuando ejecutas una serie de “comandos” guardados en
un archivo de texto, generalmente con una extensión
.pydespués del nombre de tu archivo:
SALIDA
Hello WorldIntroducción a los tipos de datos incorporados en Python
Strings, integers, and floats
Una de las cosas más básicas que podemos hacer en Python es asignar valores a las variables:
PYTHON
text = "Data Carpentry" # Un ejemplo de string
number = 42 # Un ejemplo de integer
pi_value = 3.1415 # Un ejemplo de floatAquí hemos asignado datos a las variables
text,number y pi_value,
utilizando el operador de asignación =. Para revisar el
valor de una variable, nosotros podemos escribir el nombre de la
variable en el intérprete y presionar Return:
SALIDA
"Data Carpentry"Todo en Python tiene un tipo. Para obtener el tipo de algo, podemos
pasarlo a la función type:
SALIDA
<class 'str'>SALIDA
<class 'int'>SALIDA
<class 'float'>La variable text es de tipo ‘str’, abreviatura de
string o cadena de caracteres. Las cadenas almacenan
secuencias de caracteres, que pueden ser letras, números, puntuación o
formas más exóticas de texto (¡incluso emoji!).
También podemos ver el valor de algo usando otra función incorporada,
print:
SALIDA
Data CarpentrySALIDA
11Esto puede parecer redundante, pero de hecho es la única forma de mostrar resultados en un script:
example.py
PYTHON
# En un archivo script de Python
# los comentarios en Python inician con #
# Las siguientes líneas asignan la cadena "Data Carpentry" a la variable "text".
text = "Data Carpentry"
# ¡La siguiente línea no hace nada!
text
# La siguiente línea usa la función print para imprimir el valor asignado a "text"
print(text)Ejecutando el script
SALIDA
Data CarpentryNota que “Data Carpentry” se imprime una vez.
Sugerencia: print y type
son funciones incorporadas en Python. Más adelante en esta lección,
veremos métodos y funciones definidas por el usuario. La documentación
de Python es excelente para darte una referencia sobre las diferencias
entre ellos.
Operadores
Podemos realizar cálculos matemáticos en Python usando los operadores
básicos +, -, /, *, %:
SALIDA
4SALIDA
42SALIDA
65536SALIDA
3También podemos utilizar operadores de comparación y lógicos:
<,>, ==,! =, <=,> = y declaraciones de
identidad como and, or, not. El tipo de datos devuelto por
estos operadres es llamado boolean y retorna
verdadero o falso, como ves a continuación.
SALIDA
FalseSALIDA
TrueSALIDA
TrueSALIDA
FalseSecuencias: Listas y Tuplas
Listas
list (o listas) son una estructura de datos común para almacenar una secuencia ordenada de elementos. Se puede acceder a cada elemento mediante un índice. Ten en cuenta que en Python, los índices comienzan con 0 en lugar de 1:
SALIDA
1Se puede usar un bucle for para acceder a los elementos
de una lista u otras estructuras de datos de Python, uno a la vez:
SALIDA
1
2
3Usar sangría es muy importante en Python. Ten en
cuenta que la segunda línea en el ejemplo de arriba está sangrada (o
indentada). Al igual que los tres >>> son un
indicador interactivo en Python, los tres puntos ... son
indicadores de líneas multiples en Python. Esta es la manera en que
Python marca un bloque de código. [Nota: no tienes que escribir
>>> o ....]
Para agregar elementos al final de una lista, podemos usar el método
append. Los métodos son una forma de interactuar con un
objeto (una lista, por ejemplo). Podemos invocar un método usando el
punto . seguido del nombre del método y una lista de
argumentos entre paréntesis. Veamos un ejemplo usando
append:
SALIDA
[1, 2, 3, 4]Para averiguar qué métodos están disponibles para un objeto, podemos
usar el comando incorporado help:
SALIDA
help(numbers)
Help on list object:
class list(object)
| list() -> new empty list
| list(iterable) -> new list initialized from iterable's items
...Tuplas
Una tupla tuple es similar a una lista en que es una
secuencia ordenada de elementos. Sin embargo, las tuplas no se pueden
cambiar una vez creadas (son “inmutables”). Las tuplas se crean
colocando valores separados por comas dentro de los paréntesis
().
PYTHON
# Las tuplas usan paréntesis
a_tuple = (1, 2, 3)
another_tuple = ('blue', 'green', 'red')
# Nota: las listas usan corchetes cuadrados
a_list = [1, 2, 3]Tuplas vs. Listas
- ¿Qué sucede cuando ejecutas
a_list[1] = 5? - ¿Qué sucede cuando ejecutas
a_tuple[2] = 5? - ¿Qué te dice
type(a_tuple)sobrea_tuple?
Diccionarios
Un diccionario dictionary es un contenedor que almacena pares de objetos - claves y valores.
SALIDA
1Los diccionarios funcionan como listas, excepto que se crea el índice utilizando claves keys. Puedes pensar en una clave como un nombre o un identificador único para un conjunto de valores en el diccionario. Las claves sólo pueden tener tipos particulares, tienen que ser “hashable”. Las cadenas y los tipos numéricos son aceptables, pero las listas no lo son.
SALIDA
'one'SALIDA
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'En Python, un “Traceback” es un bloque de error de varias líneas impreso para el usuario.
Para agregar un elemento al diccionario, asignamos un valor a una nueva clave:
SALIDA
{1: 'one', 2: 'two', 3: 'three'}Usar bucles for con diccionarios es un poco más
complicado. Podemos hacer esto de dos maneras:
SALIDA
1 -> one
2 -> two
3 -> threeo
SALIDA
1 -> one
2 -> two
3 -> threeCambiando diccionarios
- Primero, imprime el valor de
revdel diccionario en la pantalla. - Reasigna el segundo valor (parar el par clave: valor) para que ya no lea “dos” sino “manzana”.
- Imprime el valor de
reven la pantalla nuevamente y ve si el valor ha cambiado.
Es importante tener en cuenta que los diccionarios están “desordenados” y no recuerdan la secuencia de sus elementos (es decir, el orden en el que los pares clave: valor fueron añadidos al diccionario). Debido a esto, el orden en que los elementos son devuelto en los bucles sobre los diccionarios, puede aparecer al azar e incluso puede cambiar con el tiempo.
Funciones
Definir una sección de código como una función en Python se hace
utilizando la palabra clave def. Por ejemplo, una función
que tome dos argumentos y devuelve su suma puede ser definida como:
SALIDA
42- Python es un lenguaje interpretado que puede ser usado interactivamente (ejecutando un comando a la vez) o en modo scripting (ejecutando una serie de comandos guardados en un archivo).
- Se puede asignar un valor a una variable en Python. Esas variables pueden ser de varios tipos, tales como cadenas, y números: enteros, de punto flotante y complejos.
- Las listas y las tuplas son similares en el sentido de que son listas ordenadas de elementos; difieren en que una tupla es inmutable (sus elementos no pueden ser modificados).
- Los diccionarios son estructuras de datos desordenadas que proporcionan mapeos entre claves y valores.
Content from Comenzando con datos
Última actualización: 2023-02-07 | Mejora esta página
Trabajando con Pandas DataFrames en Python
Hoja de ruta
Preguntas
- ¿Cómo importar datos en Python?
- ¿Qué es Pandas?
- ¿Por qué debería de usar Pandas para trabajar con datos?
Objetivos
- Explorar el directorio del taller y descargar el dataset.
- Explicar qué es una biblioteca y para qué se usa.
- Describir qué es, Pandas, la Biblioteca de Análisis de Datos de Python.
- Cargar Pandas, la biblioteca de Análisis de Datos de Python.
- Usar
read_csvpara leer datos tabulares en Python. - Describir qué es un DataFrame en Python.
- Acceder y resumir datos guardados en un DataFrame.
- Definir la indexación y su relación con las estructuras de datos.
- Ejecutar operaciones matemáticas básicas y calcular estadísticas descriptivas sobre datos dentro de un Pandas Dataframe.
- Crear gráficos simples.
Podemos automatizar el proceso de manipular datos con Python. Vale la pena pasar tiempo escribiendo el código que haga estas tareas ya que una vez que se escribió, lo podemos usar una y otra vez en distintos conjuntos de datos que usen un formato similar. Esto hace a nuestros métodos fácilmente reproducibles. También resulta fácil compartir nuestro código con nuestros colegas y ellos pueden replicar el mismo análisis.
Comenzando en el mismo lugar
Para que la lección salga de la mejor manera posible, vamos a asegurarnos que todos estemos en el mismo directorio. Esto debería ayudarnos a evitar inconvenientes con los nombres de los directorios y los archivos. Navega al directorio del taller. Si tu estás trabajando en IPython Notebook asegurate de iniciar tu notebook en el directorio del taller.
Un comentario al margen es que hay bibliotecas de Python, como OS Library, las cuales pueden trabajar con la estructra de directorios, sin emebargo este no es nuestro objetivo el día de hoy.
Nuestros datos
Para esta lección, usaremos los datos de “Portal Teaching” que son subconjunto de los datos estudiados por Ernst et al. Long-term monitoring and experimental manipulation of a Chihuahuan Desert ecosystem near Portal, Arizona, USA.
Usaremos los datos de Portal
Project Teaching Database. Esta sección usa el archivo
surveys.csv el cual puede ser descargado desde: https://ndownloader.figshare.com/files/2292172
Vamos a estudiar la especie y el peso de los animales capturados en
sitios dentro de nuestra área de estudio. El conjunto de datos esta
guardado en un archivo .csv: cada línea tiene información
sobre un solo animal y las columnas representan:
| Columna | Descripción |
|---|---|
| record_id | identificador único de la observación |
| month | mes de observación |
| day | día de la observación |
| year | año de la observación |
| plot_id | ID de un sitio en particular |
| species_id | código de dos letras |
| sex | sexo del animal (“M”, “F”) |
| hindfoot_length | tamaño de pata en mm |
| weight | peso del animal en gramos |
Las primeras líneas de nuestro archivo se ven de la siguiente manera:
SALIDA
record_id,month,day,year,plot_id,species_id,sex,hindfoot_length,weight
1,7,16,1977,2,NL,M,32,
2,7,16,1977,3,NL,M,33,
3,7,16,1977,2,DM,F,37,
4,7,16,1977,7,DM,M,36,
5,7,16,1977,3,DM,M,35,
6,7,16,1977,1,PF,M,14,
7,7,16,1977,2,PE,F,,
8,7,16,1977,1,DM,M,37,
9,7,16,1977,1,DM,F,34,Acerca de las bibliotecas
Una biblioteca en Python contiene un conjunto de herramientas (llamadas funciones) que hacen tareas en nuestros datos. Importar una biblioteca es como traer un la pieza de laboratorio de nuestro locker y montarla en nuestra mesa de trabajo para usarla en nuestro proyecto. Una vez que la bilioteca está instalada, puede ser usada y llamada para hacer muchas tareas.
Pandas en Python
Una de las mejores opciones para trabajar con datos tabulares en Python es usar la Python Data Analysis Library (alias Pandas). La biblioteca Pandas provee estructuras de datos, genera gráficos de alta calidad con matplotlib y se integra de buena forma con otras bibliotecas que usan arrays de NumPy (la cual es otra biblioteca de Python).
Python no carga todas las bibliotecas disponibles por default. Se
tiene que usar el enunciado import en nuestro código para
usar las funciones de la biblioteca. Para importar una biblioteca se usa
la sintaxis import nombreDeLaBiblioteca. Si además le
queremos poner un sobrenombre para acortar los comandos, se puede
agregar as sobrenombreAUsar. Un ejemplo es importar la
biblioteca pandas usando su sobrenombre común pd como está
aquí abajo.
Cada vez que llamemos a una función que está en la biblioteca, se usa
la sintaxis NombreDeLaBiblioteca.NombreDeLaFuncion. Agregar
el nombre de la biblioteca con un . antes del nombre de la
función le indica a Python donde encontrar la función. En el ejemplo
anterior hemos importado a Pandas como pd. Esto significa
que no vamos a tener que escribir pandas cada vez que
llamemos a una función de Pandas y solo lo hagamos con su
sobrenombre.
Leyendo datos en CSV usando Pandas
Empezaremos encontrando y leyendo los datos del censo que están en
formato CSV. CSV son las siglas para Comma-Separated Values,
valores separados por coma, y es una manera común de guardar datos.
Otros símbolos pueden ser usados, te puedes encontrar valores separados
por tabuladores, por punto y coma o por espacios en blanco. Es fácil
remplazar un separador por otro, para usar tu aplicación. La primera
línea del archivo generalmente contiene los encabezados que dicen que
hay en cada columna. CSV (y otros separadores) hacen fácil compartir los
datos y pueden ser importados y exportados desde distintos programas,
incluyendo Microsoft Excel. Para más detalles sobre los archivos CSV, ve
la lección Organización
de datos en hojas de cálculo. Podemos usar la función de Pandas
read_csvpara abrir el archivo directamente en un DataFrame.
Entonces, ¿qué es un DataFrame?
Un DataFrame es una estructura de datos con dos
dimensiones en la cual se puede guardar datos de distintos tipos (como
caractéres, enteros, valores de punto flotante, factores y más) en
columnas. Es similar a una hoja de cálculo o una tabla de SQL o el
data.frame de R. Un DataFrame siempre
tiene un índice (con inicio en 0). El índice refiere a la posición de un
elemento en la estructura de datos.
PYTHON
# Observa que se usa pd.read_csv debido a que importamos a pandas como pd
pd.read_csv("data/surveys.csv")El comando anterior lleva a la siguiente salida:
SALIDA
record_id month day year plot_id species_id sex hindfoot_length weight
0 1 7 16 1977 2 NL M 32 NaN
1 2 7 16 1977 3 NL M 33 NaN
2 3 7 16 1977 2 DM F 37 NaN
3 4 7 16 1977 7 DM M 36 NaN
4 5 7 16 1977 3 DM M 35 NaN
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[35549 rows x 9 columns]Podemos ver que se leyeron 35,549 líneas. Cada una de los líneas
tiene 9 columnas. La primera columna es el índice del DataFrame. El
índice es usado para identificar la posición de los datos, pero no es
una columna del DataFrame. Parace ser que la función
read_csvde Pandas leyó el archivo correctamente. Sin
embargo, no hemos salvado ningún dato en memoria por lo que no podemos
trabajar con estos. Necesitamos asignar el DataFrame a
una variable. Recuerda que una variable es el nombre para un valor, como
xo data. Podemos crear un nuevo objeto con el
nombre de la variable y le asignamos un valor usando =.
Llamemos los datos del censo importados surveys_df:
Notemos que cuando asignamos los datos importado a un
DataFrame a una variable, Python no produce ninguna
salida a pantalla. Podemos ver el contenido de surveys_df
escribiendo el nombre en la línea de comando de Python.t.
el cual imprime los contenidos como anteriormente.
Nota: si la salida es más ancha que la pantalla de teminal al imprimirlo se verá algo distinto conforme el gran conjunto de datos pasa. Se podría ver simplemente la última columna de los datos:
SALIDA
17 NaN
18 NaN
19 NaN
20 NaN
21 NaN
22 NaN
23 NaN
24 NaN
25 NaN
26 NaN
27 NaN
28 NaN
29 NaN
... ...
35519 36.0
35520 48.0
35521 45.0
35522 44.0
35523 27.0
35524 26.0
35525 24.0
35526 43.0
35527 NaN
35528 25.0
35529 NaN
35530 NaN
35531 43.0
35532 48.0
35533 56.0
35534 53.0
35535 42.0
35536 46.0
35537 31.0
35538 68.0
35539 23.0
35540 31.0
35541 29.0
35542 34.0
35543 NaN
35544 NaN
35545 NaN
35546 14.0
35547 51.0
35548 NaN
[35549 rows x 9 columns]No temas, todos los datos están ahí, si tu navegas hacía arriba de tu terminal. Seleccionemos solo algunas de las líneas, esto hara más facil que la salida quepa en una terminal, se puede ver que Pandas formateo los datos de tal manera que quepan en la pantalla:
PYTHON
surveys_df.head() # The head() method displays the first several lines of a file. It
# is discussed below.SALIDA
record_id month day year plot_id species_id sex hindfoot_length \
5 6 7 16 1977 1 PF M 14.0
6 7 7 16 1977 2 PE F NaN
7 8 7 16 1977 1 DM M 37.0
8 9 7 16 1977 1 DM F 34.0
9 10 7 16 1977 6 PF F 20.0
weight
5 NaN
6 NaN
7 NaN
8 NaN
9 NaNExplorando los datos del censo de especies
Una vez más podemos usar la función type para ver que
cosa es surveys_df:is:
SALIDA
<class 'pandas.core.frame.DataFrame'>Como podíamos esperar, es un DataFrame (o, usando el
nombre completo por el cual Python usa internamente, un
pandas.core.frame.DataFrame).
¿Qué tipo de cosas surveys_df contiene? Los
DataFrame tienen un atributo llamado
dtypes que contesta esta pregunta:
SALIDA
record_id int64
month int64
day int64
year int64
plot_id int64
species_id object
sex object
hindfoot_length float64
weight float64
dtype: objectTodos los valores de una columna tienen el mismo tipo. Por ejemplo,
months tienen el tipo int64, el cual es un tipo de entero.
Las celdas en la columna de mes no pueden tener valores fraccionarios,
pero las columnas de weight y hindfoot_length
pueden, ya que son de tupo float64. El tipo
object no tiene un nombre muy útil, pero en ete caso
representa una palabra (como ‘M’ y ‘F’ en el caso del sexo).
En otra lección discutiremos sobre el significado de los distintos tipos.
Formas útiles de ver objetos DataFrame en Python
Hay distintas maneras de resumir y accesar a los datos guardados en un DataFrame, usando los atributos y métodos que proveé el objeto DataFrame.
Para accesar a un atributo, se usa el nombre del objeto
DataFrame seguido del nombre del atributo
df_object.attribute. Usando el DataFrame
surveys_df y el atributo columns, un índice de
todos los nombres de las columnas en el DataFrame puede
ser accesado con surveys_df.columns.
Métodos son llamados de la misma manera usando la sintáxis
df_object.method(). Como ejemplo,
surveys_df.head() obtiene las primeros líneas del
DataFrame surveys_df usando el
método head(). Con un método, podemos proporcionar
información extra en los padres para contreol su comportamiento.
Echemos un ojo a los datos usando este.
Reto - DataFrames
Usando nuestro DataFrame surveys_df,
ejecuta los atributos y métodos siguientes y observa que regresan.
surveys_df.columnssurveys_df.shapeToma nota de la salida deshape- ¿Qué formato tiene la salida del atributo que regresa la forma de un DataFrame?
Sugerencia: Más acerca de tuplas, aquí.
surveys_df.head()También ejecutasurveys_df.head(15)¿qué hace esto?surveys_df.tail()
Calculando estadísticas de los datos en un DataFrame de Pandas
Hemos leídos los datos en Python. Ahora calculemos algunas estadísticas para entender un poco de los datos con los que estamos trabajando. Podríamos querer saber cuántos animales fueron colectados en cada sitio, o cuántos de cada especie fueron capturados. Podemos calcular estas estadísticas rápidamente usando grupos. Pero antes tenemos que saber como los queremos argupar.
Empezemos a explorar los datos:
lo que regresa:
SALIDA
Index(['record_id', 'month', 'day', 'year', 'plot_id', 'species_id', 'sex',
'hindfoot_length', 'weight'],
dtype='object')Obtengamos una lista de todas las especies. La función
pd.unique nos dice los distintos valores presentes en la
columnaspecies_id.
lo que regresa:
PYTHON
array(['NL', 'DM', 'PF', 'PE', 'DS', 'PP', 'SH', 'OT', 'DO', 'OX', 'SS',
'OL', 'RM', nan, 'SA', 'PM', 'AH', 'DX', 'AB', 'CB', 'CM', 'CQ',
'RF', 'PC', 'PG', 'PH', 'PU', 'CV', 'UR', 'UP', 'ZL', 'UL', 'CS',
'SC', 'BA', 'SF', 'RO', 'AS', 'SO', 'PI', 'ST', 'CU', 'SU', 'RX',
'PB', 'PL', 'PX', 'CT', 'US'], dtype=object)Reto - Estadísticas
Crear una lista de los IDs de los sitios (“plot_id”) que están en los datos del censo. Llamamemos a esta lista
site_names. ¿Cuántos sitios hay en los datos?, ¿cuántas especies hay en los datos?¿Cuál es la diferencia entre
len(site_names)ysurveys_df['plot_id'].nunique()?
Grupos en Pandas
En algunas ocasiones queremos calcular estadísticas de datos agrupados por subconjuntos o atributos de nuestros datos. Por ejemplo, si queremos calcular el promedio de peso de nuestros individuos por sitio.
Podemos calcular algunas estadísticas básica de todos los datos en una columna usando el siguiente comando:
nos devuelve la siguiente salida
PYTHON
count 32283.000000
mean 42.672428
std 36.631259
min 4.000000
25% 20.000000
50% 37.000000
75% 48.000000
max 280.000000
Name: weight, dtype: float64También podemos extraer una métrica en particular::
PYTHON
surveys_df['weight'].min()
surveys_df['weight'].max()
surveys_df['weight'].mean()
surveys_df['weight'].std()
surveys_df['weight'].count()Pero si nosotros queremos extraer información por una o más
variables, por ejemplo sexo, podemos usar el método
.groupby de Pandas. Una vez que creamos un
DataFrame groupby, podemos calcular estadísticas por el
grupo de nuestra elección.
La función describe de Pandas regresa
estadísticas descriptivas incluyendo: media, meadiana, máx, mín, std y
conteos para una columna en particular de los datos. La función
describe solo regresa los valores de estas estadísticas
para las columnas numéricas.
PYTHON
# Estadísticas para todas las columnas numéricas por sexo
grouped_data.describe()
# Regresa la media de cada columna numérica por sexo
grouped_data.mean()grouped_data.mean() SALIDA:
PYTHON
record_id month day year plot_id \
sex
F 18036.412046 6.583047 16.007138 1990.644997 11.440854
M 17754.835601 6.392668 16.184286 1990.480401 11.098282
hindfoot_length weight
sex
F 28.836780 42.170555
M 29.709578 42.995379El comando groupby es muy potente y no permite
rápidamente generar estadísticas descriptivas.
Reto - Descripción de datos
- ¿Cuántos individuos son hembras
Fy cuántos son machosM? - Qué pasa cuando agrupas sobre dos columnas usando el siguiente enunciado y después tomas los valores medios:
grouped_data2 = surveys_df.groupby(['plot_id','sex'])grouped_data2.mean()
- Calcula las estadísticas descriptivas del peso para cada sitio.
Sugerencia: puedes usar la siguiente sintaxis para solo crear las
estadísticas para una columna de tus datos
by_site['weight'].describe()
Un pedaxo de la salida para el reto 3 se ve así:
SALIDA
site
1 count 1903.000000
mean 51.822911
std 38.176670
min 4.000000
25% 30.000000
50% 44.000000
75% 53.000000
max 231.000000
...Creando estadísticas de conteos rapidamente con Pandas
Ahora contemos el número de muestras de cada especie. Podemos hacer
esto de dsitintas maneras, pero usaremos groupby combinada
con el método count().
PYTHON
# Cuenta el número de muestras por especie
species_counts = surveys_df.groupby('species_id')['record_id'].count()
print(species_counts)O, también podemos contar las líneas que tienen la especie “DO”:
Reto - Haciendo una lista
¿Qué otra manera hay de crear una lista de especies y asociarle
count de las muestras de los datos? Sugerencia: puedes
hacer ejecutar las funciones count, min, etc.
en un DataFrame groupby de la misma manera de la que se
hace en un DataFrame
Graficar rápida y fácilmente los datos usando Pandas
También podemos gráficar nuestras estadísticas descriptivas usando Pandas.
PYTHON
# Aseguremonos de que las imágenes aparezcan insertadas en iPython Notebook
%matplotlib inline
# Creaemos una gráfica de barras
species_counts.plot(kind='bar');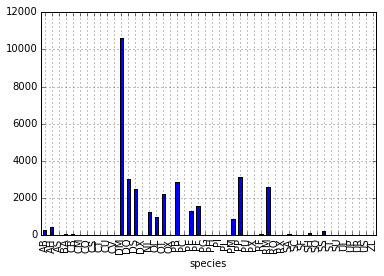 Conteos de especie por sitio
Conteos de especie por sitio
También podemos ver cuantos animales fueron capturados por sitio:
PYTHON
total_count = surveys_df.groupby('plot_id')['record_id'].nunique()
# También grafiquemos eso
total_count.plot(kind='bar');Reto - Gráficas
- Crea una gráfica del promedio de peso de las especies por sitio.
- Crea una gráfica del total de machos contra el total de hembras para todo el conjunto de datos.
Reto de graficación final
Crea una gráfica de barras apiladas con el peso en el eje Y, y la variable de apilamiento que sea el sexo. La gráfica debe mostrar el peso total por sexo para cada sitio. Algúnos tips que te pueden ayudar a resolver el reto son los siguientes:
- Para mayor información en gráfica con Pandas, visita la siguiente liga.
- Puedes usar el siguiente código para crear una gráficad de barras apiladas pero los datos para apilar deben de estar en distintas columnas. Aquí hay un pequeño ejemplo con algunos datos donde ‘a’, ‘b’ y ‘c’ son los grupos, y ‘one’ y ‘two’ son los subgrupos.
PYTHON
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
pd.DataFrame(d)muestra los siguientes datos
SALIDA
one two
a 1 1
b 2 2
c 3 3
d NaN 4Podemos gráficar esto con
PYTHON
# Graficar datos apilados de modo que las columnas 'one' y 'two' estén apiladas
my_df = pd.DataFrame(d)
my_df.plot(kind='bar',stacked=True,title="The title of my graph")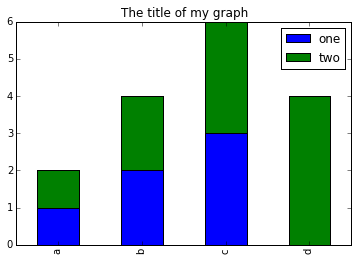
- Podemos usar el método
.unstack()para transformar los datos agrupados en columnas para cada gráfica. Intenta ejecutar.unstack()en algún DataFrame anterior y observa a que lleva.
Empieza transformando los datos agrupados (por sitio y sexo) en una disposición desapilada entonces crea una gráfica apilada.
Primero agrupemos los datos por sitio y por sexo y después calculemos el total para cada sitio.
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()Esto calcula la suma de los pesos para cada sexo por sitio como una tabla
SALIDA
site sex
plot_id sex
1 F 38253
M 59979
2 F 50144
M 57250
3 F 27251
M 28253
4 F 39796
M 49377
<lo demás fue omitido para abreviar>Ahora usaremos .unstack() en los datos agrupados para
entender como el peso total de cada sexo contribuye a cada sitio.
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()
site_sex_count.unstack()El método unstack de arriba despliega la siguiente
salida:
SALIDA
sex F M
plot_id
1 38253 59979
2 50144 57250
3 27251 28253
4 39796 49377
<los demás sitios son omitido por brevedar>Ahora creamos una gráfica de barras apilada con los datos donde el peso para cada sexo es apilado por sitio.
En vez de mostrarla como tabla, nosotros podemos graficar los datos apilando los datos de cada sexo como sigue:
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()
spc = site_sex_count.unstack()
s_plot = spc.plot(kind='bar',stacked=True,title="Total weight by site and sex")
s_plot.set_ylabel("Weight")
s_plot.set_xlabel("Plot")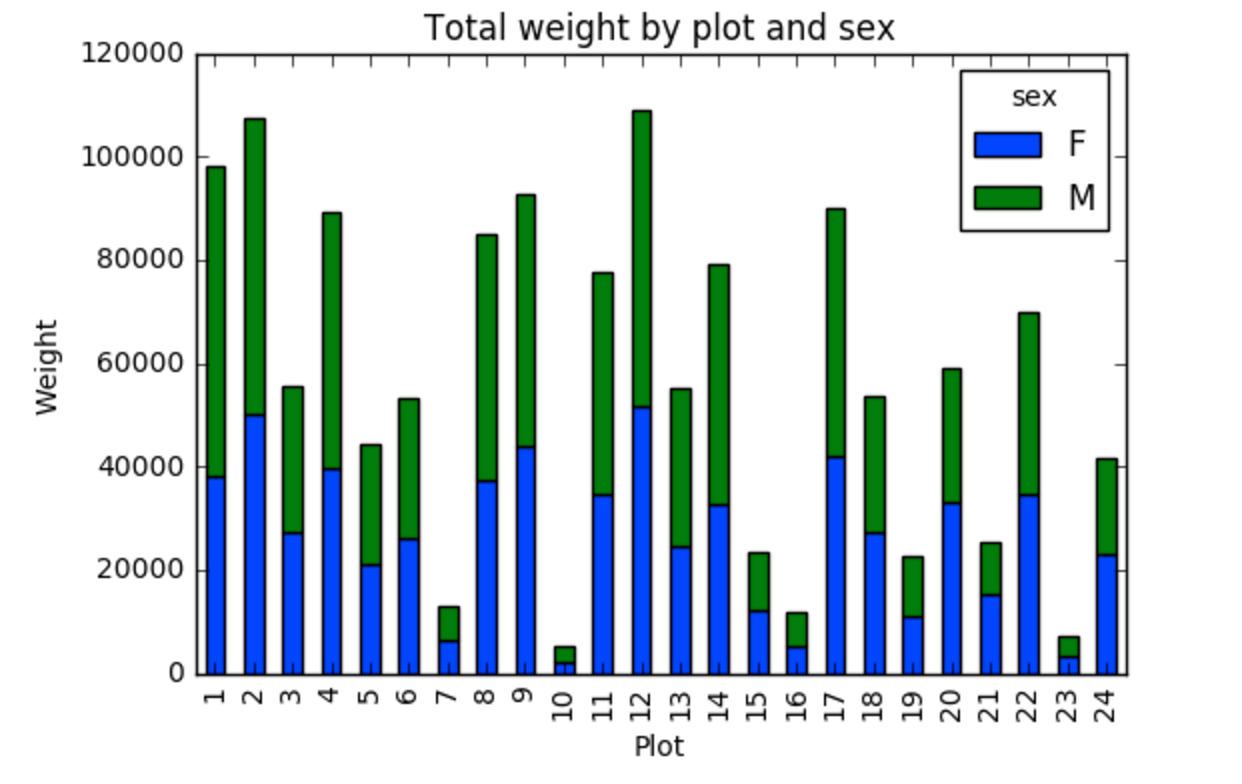
- Las bibliotecas en Python son conjuntos de herramientas, funciones y estructuras de datos, agrupadas de forma conveniente para facilitar nuestro trabajo.
- Pandas es una librería que ofrece funcionalidades avanzadas para manejar datos tabulares, procesarlos y obtener resultados similares a los que ofrecen las hojas de cálculo.
- El DataFrame es la estructura de datos fundamental de Pandas, representa una tabla de datos panel con indexación integrada. Cada columna contiene los valores de una variable y cada fila un conjunto de valores de cada columna.
- Un índice es un vector inmutable, ordenado y divisible, que almacena las etiquetas de los ejes de todas las estructuras de Pandas. Se utiliza para agrupar y seleccionar de distintas maneras el contenido de un DataFrame.
- Pandas ofrece funcionalidades que permiten realizar operaciones matemáticas, calcular estadísticas y generar gráficos a partir del contenido de una Serie o DataFrame.
Content from Indexación, segmentación y creación de subconjuntos a partir de DataFrames en Python
Última actualización: 2023-02-07 | Mejora esta página
En la lección 01, leímos un archivo CSV y cargamos los datos en un pandas DataFrame. Aprendimos:
Hoja de ruta
Preguntas
- ¿Cómo puedo acceder a un dato específico en mi ‘dataset’?
- ¿Cómo pueden ayudarme Python y Pandas a analizar mis datos?
Objetivos
- Describir que es indexación en base-0.
- Manipular y extraer datos usando encabezados de columnas e índices.
- Usar ‘slicing’ para seleccionar conjuntos de datos de un ‘DataFrame’.
- Emplear etiquetas e índices enteros para seleccionar rangos de datos en un ‘DataFrame’.
- Reasignar valores dentro de subconjuntos de datos de un ‘DataFrame’.
- Crear una copia de un ‘DataFrame’.
- Consultar/Seleccionar un subconjunto de datos usando un conjunto de criterios utilizando los siguientes operadores: =, !=, >, <, >=, <=.
- Localizar subconjuntos de datos utilizando máscaras.
- Describir objetos tipo ‘boolean’ en Python y manipular datos usando ‘booleans’.
- como guardar el DataFrame en un objeto,
- como realizar operaciones matemáticas básica sobre datos,
- como calcular resúmenes estadísticos, y
- como crear gráficos a partir de los datos.
En esta lección, exploraremos formas de acceder a diferentes partes de los datos usando:
- indexación,
- segmentación, y
- creación de subconjuntos.
Cargando nuestros datos
Vamos a continuar usando el dataset surveys que usamos con la lección anterior. Reabrámoslo y leamos los datos de nuevo:
Indexando y Fragmentando en Python
A menudo necesitamos trabajar con subconjuntos de un objeto DataFrame. Existen diferentes maneras de lograr esto, incluyendo: usando etiquetas (encabezados de columnas), rangos numéricos, o índices de localizaciones específicas x,y.
Seleccionando datos mediante el uso de Etiquetas (Encabezados de Columnas)
Utilizamos corchetes [] para seleccionar un subconjunto
de un objeto en Python. Por ejemplo, podemos seleccionar todos los datos
de una columna llamada species_id del
surveys_df DataFrame usando el nombre de
la columna. Existen dos maneras de hacer esto:
PYTHON
# Sugerencia: usa el método .head() que vimos anteriormente para hacer la salida más corta
# Método 1: selecciona un 'subconjunto' de los datos usando el nombre de la columna
surveys_df['species_id']
# Método 2: usa el nombre de la columna como un 'atributo'; esto produce la misma salida
surveys_df.species_idTambién podemos crear un nuevo objeto que contiene solamente los
datos de la columna species_id de la siguiente manera:
PYTHON
# Crea un objeto, `surveys_species`, que solamente contenga la columna `species_id`
surveys_species = surveys_df['species_id']También podemos pasar una lista de nombres de columnas, a manera de índice para seleccionar las columnas en ese orden. Esto es útil cuando necesitamos reorganizar nuestros datos.
NOTA: Si el nombre de una columna no esta incluido
en el DataFrame, se producirá una excepción (error).
PYTHON
# Selecciona las especies y crea un gráfico con las columnas del **DataFrame**
surveys_df[['species_id', 'plot_id']]
# ¿Qué pasa cuando invertimos el orden?
surveys_df[['plot_id', 'species_id']]
# ¿Qué pasa si preguntamos por una columna que no existe?
surveys_df['speciess']Python nos informa que tipo de error es en el rastreo, en la parte
inferior dice KeyError: 'speciess' lo que significa que
speciess no es un nombre de columna (o Key
que está relacionado con el diccionario de tipo de datos de Python).
Extrayendo subconjuntos basados en rangos: Segmentando
RECORDATORIO: Python usa Indexación en base-0
Recordemos que Python usa indexación en base-0. Esto quiere decir que el primer elemento en un objeto esta localizado en la posición 0. Esto es diferente de otros lenguajes como R y Matlab que indexan elementos dentro de objetos iniciando en 1.

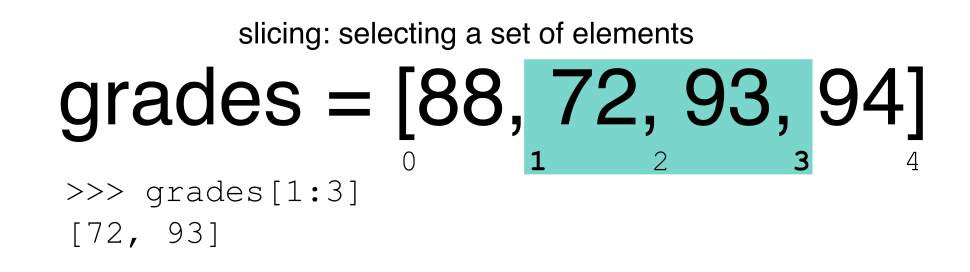
Segmentando Subconjuntos de Filas en Python
La segmentación utilizando el operador [] selecciona un
conjunto de filas y/o columnas de un DataFrame. Para
segmentar un conjunto de filas, usa la siguiente sintaxis:
data[start:stop]. Cuando se hace segmentación en pandas, el
límite inicial (start) se incluye en los datos de
salida. El límite final (stop) es un paso MÁS ALLÁ de
la fila que desea seleccionar. Así que si deseas seleccionar las filas
0, 1 y 2, tu código se vería así:
El límite final en Python es diferente del que puedes estar acostumbrado a usar en Lenguajes como Matlab y R.
PYTHON
# Selecciona las primeras cinco filas (con índices 0, 1, 2, 3, 4)
surveys_df[:5]
# Selecciona el último elemento de la lista
# (el segmento comienza en el último elemento y finaliza al final de la lista)
surveys_df[-1:]También podemos reasignar valores dentro de subconjuntos de nuestro DataFrame.
Pero antes de hacerlo, veamos la diferencia entre el concepto de copiar objetos y el concepto de referenciar objetos en Python.
Copiar Objetos vs Referenciar Objetos en Python
Empecemos con un ejemplo:
PYTHON
# Usando el método 'copy()'
true_copy_surveys_df = surveys_df.copy()
# Usando el operador '='
ref_surveys_df = surveys_dfPuedes pensar que el código ref_surveys_df = surveys_df
crea una copia nueva y distinta de objeto DataFrame
surveys_df. Sin embargo, usar el operador = en
una instrucción simple de la forma y = x
no crea una copia de nuestro
DataFrame. En lugar de esto, y = x crea
una variable nueva y que hace referencia al
mismo objeto al que x hace referencia.
Para decirlo de otra manera, solamente hay un objeto
(el DataFrame), y ambos objetos x y
y hacen referencia a él.
En contraste, el método copy() de un
DataFrame crea una copia verdadera del
DataFrame.
Veamos lo que sucede cuando reasignamos los valores dentro de un subconjunto del DataFrame que hace referencia a otro objeto DataFrame:
PYTHON
# Asigna el valor `0` a las primeras tres filas de datos en el **DataFrame**
ref_surveys_df[0:3] = 0Probemos el siguiente código:
PYTHON
# ref_surveys_df fue creado usando el operador '='
ref_surveys_df.head()
# surveys_df es el **DataFrame** original
surveys_df.head()¿Cuál es la diferencia entre estos dos DataFrames?
Cuando asignamos a las tres primeras filas el valor de 0
usando el DataFrame ref_surveys_df, el
DataFrame surveys_df también es
modificado. Recuerda que creamos el objeto ref_survey_df
arriba usando la instrucción ref_survey_df = surveys_df.
Por lo tanto surveys_df y ref_surveys_df hacen
referencia exactamente al mismo objeto DataFrame. Si
cualquiera de los dos objetos (ref_survey_df,
surveys_df) es modificado, el otro objeto va a observar los
mismos cambios.
Revisar y Recapitular:
-
Para crear una copia de un objeto, usamos el método copy() de un
DataFrame -
Para crear una referencia a un objeto usamos el operador
=
Muy bien, hora de practicar. Vamos a crear un nuevo objeto
DataFrame a partir del archivo CSV con los datos
originales.
Segmentando subconjuntos de filas y columnas en Python
Podemos seleccionar subconjuntos de datos, contenidos en rangos específicos de filas y columnas, usando etiquetas o indexación basada en números enteros.
-
loces usado principalmente para indexación basada en etiquetas. Permite usar números enteros pero son interpretados como una etiqueta. -
iloces usado para indexación basada en números enteros
Para seleccionar un subconjunto de filas y columnas
de nuestro objeto DataFrame, podemos usar el método
iloc. Por ejemplo, podemos seleccionar month,
day y year (que corresponden a las columnas 2,
3 y 4, si empezamos a contar las columnas en 1) para las primeras tres
filas, de la siguiente manera:
lo cual nos produce la siguiente salida
SALIDA
month day year
0 7 16 1977
1 7 16 1977
2 7 16 1977Ten en cuenta que pedimos un segmento de 0:3. Esto produjo 3 filas de datos. Cuando pides un segmento de 0:3, le estas diciendo a Python que comience en el índice 0 y seleccione las filas 0, 1, 2, hasta 3 pero sin incluir esta última.
Exploremos otras maneras de indexar y seleccionar subconjuntos de datos:
PYTHON
# Selecciona todas las columnas para las filas con índices entre 0 y 10
surveys_df.loc[[0, 10], :]
# ¿Qué salida produce el la siguiente instrucción?
surveys_df.loc[0, ['species_id', 'plot_id', 'weight']]
# ¿Qué pasa cuando ejecutas el siguiente código?
surveys_df.loc[[0, 10, 35549], :]NOTA: Las etiquetas utilizadas deben estar incluidas
en el DataFrame o se obtendrá un error de tipo
KeyError.
La indexación por etiquetas (loc) difiere de la
indexación por números enteros (iloc). Cuando usamos
loc, los limites inicial y final se
incluyen. Cuando usamos loc,
podemos usar números enteros, pero dichos números enteros harán
referencia a etiquetas usadas a manera de índice y no a la posición. Por
ejemplo, si usamos loc y seleccionamos 1:4 vamos a obtener
resultados diferentes que si usamos iloc para seleccionar
las filas 1:4.
Podemos seleccionar un dato específico utilizando la la intersección
de una fila y una columna dentro del DataFrame, junto con
la indexación basada en números enteros iloc:
PYTHON
# Sintaxis para encontrar un dato especifico dentro de un `DataFrame` utilizando indexación `iloc`
dat.iloc[fila, columna]En este ejemplo de iloc,
la salida es la siguiente
SALIDA
'F'Recuerda que la indexación en Python inicia en 0. Así que, la
direccíon basada en índice [2, 6] selecciona el elemento ubicado en la
intersección de la tercera fila (índice 2) y la séptima columna (índice
6) en el DataFrame.
Desafío - Rangos
- ¿Qué ocurre al ejecutar el siguiente código?:
surveys_df[0:1]surveys_df[:4]surveys_df[:-1]
- ¿Qué pasa al ejecutar este otro?:
dat.iloc[0:4, 1:4]dat.loc[0:4, 1:4]¿Qué diferencia observas entre los resultados de los comandos inmediatamente anteriores?
Creando subconjuntos de datos mediante el filtrado por criterios
También podemos seleccionar un subconjunto de nuestros datos,
mediante el filtrado de la data original, usando algún criterio. Por
ejemplo, podemos seleccionar todas las filas que tienen el valor de 2002
en la columna year:
Lo cual produce la siguiente salida:
PYTHON
record_id month day year plot_id species_id sex hindfoot_length weight
33320 33321 1 12 2002 1 DM M 38 44
33321 33322 1 12 2002 1 DO M 37 58
33322 33323 1 12 2002 1 PB M 28 45
33323 33324 1 12 2002 1 AB NaN NaN NaN
33324 33325 1 12 2002 1 DO M 35 29
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[2229 rows x 9 columns]También podemos seleccionar todas las filas que no contienen el año 2002:
También podemos definir conjuntos de criterios:
Hoja de referencia para sintaxis de Python
Podemos utilizar la sintaxis incluida a continuación, cuando queramos
hace consultas de datos por criterios en un DataFrame.
Experimenta seleccionando varios subconjuntos de los datos contenidos en
surveys_df.
- Igual a:
== - No igual o diferente de:
!= - Mayor que, menor que:
>or< - Mayor o igual que
>= - Menor o igual que
<=
Desafío - Consultas
Selecciona un subconjunto de filas, en el
DataFramesurveys_df, que contenga datos desde el año 1999 y que contenga valores enweightmenores o iguales a 8. ¿Cuántas filas obtuviste como resultado? ¿Cuántas filas obtuvo tu compañera?Puedes usar la función
isinde Python para hacer una consulta a unDataFrame, basada en una lista de valores según se muestra a continuación:
Usa la función isin para encontrar todos los
plots que contienen una especie en particular en el
DataFrame surveys_df. ¿Cuántos registros
contienen esos valores?
Experimenta con otras consultas. Crea una consulta que encuentre todas las filas con el valor de
weightmayor o igual a 0.El símbolo
~puede ser usado en Python para obtener lo opuesto a los datos seleccionados que hayas especificado. Es equivalente a no esta en. Escribe una consulta que seleccione todas las filas consexdiferente de ‘M’ o ‘F’ en los datos desurveys_df.
Usando máscaras para identificar una condición específica
Una máscara puede ser útil para identificar donde
existe o no exite un subconjunto específico de valores - por ejemplo,
NaN, o Not a Number en inglés. Para enternder el
concepto de máscaras, también tenemos que entender los objetos
BOOLEAN en Python.
Valores boleanos (boolean) incluyen
True o False. Por ejemplo,
PYTHON
# Asigna 5 a la variable x
x = 5
# ¿Qué nos devuelve la ejecución del siguiente código?
x > 5
# ¿Qué nos devuelve la ejecución de este?
x == 5Cuando le preguntamos a Python ¿Cuál es el valor de
x > 5?, obtenemos False. Esto se debe a que
la condición x es mayor que 5, no se cumple dado que
x es igual a 5.
Para crear una máscara booleana:
- Establece el criterio a ser evaluado como
TrueoFalse(ej.values > 5 = True) - Python evaluará cada valor en el objeto para determinar si el valor
cumple el criterio (
True) o no lo cumple (False). - Python crea un objeto de salida que es de la misma forma que el
objeto original, pero con un valor
TrueoFalsepor cada índice según corresponda.
Intentémoslo. Vamos a identificar todos los lugares en los datos de
survey que son null (que no existen o son
NaN). Podemos usar el método isnull para lograrlo. El
método isnull va a comparar cada celda con un valor
null. Si un elemento tiene un valor null, se
le asignará un nuevo valor de True en el objeto de
salida.
Un fragmento de la salida se muestra a continuación:
PYTHON
record_id month day year plot_id species_id sex hindfoot_length weight
0 False False False False False False False False True
1 False False False False False False False False True
2 False False False False False False False False True
3 False False False False False False False False True
4 False False False False False False False False True
[35549 rows x 9 columns]Para seleccionar las filas donde hay valores null,
podemos utilizar una máscara a manera de índice y obtener subconjuntos
de datos así:
PYTHON
# Para seleccionar solamente las filas con valores NaN, podemos utilizar el método 'any()'
surveys_df[pd.isnull(surveys_df).any(axis=1)]Nota que la columna weight de nuestro
DataFrame contiene varios valores null o
NaN. Exploraremos diferentes maneras de abordar esto en el
episodio de tipos
de datos y formatos.
También podemos utilizar isnull en una columna en
particular. ¿Qué salida produce el siguiente código?
PYTHON
# ¿Qué hace el siguiente código?
empty_weights = surveys_df[pd.isnull(surveys_df['weight'])]['weight']
print(empty_weights)Tomemos un minuto para observar las instrucciones de arriba. Estamos
usando el objeto booleano pd.isnull(surveys_df['weight']) a
manera de índice para surveys_df. Estamos pidiendo a Python
que seleccione aquellas filas que tienen un valor de NaN en
la columna weight.
Desafío - Revisando todo lo aprendido
Crea un nuevo objeto
DataFrameque solamente contenga observaciones cuyos valores en la columnasexno seanfemaleomale. Asigna cada valor desexen el nuevoDataFramea un nuevo valor de ‘x’. Determina el número total de valoresnullen el subconjunto.Crea un nuevo objeto
DataFrameque contenga solo observaciones cuyos valores en la columnasexseanmaleofemaley en los cuales el valor deweightsea mayor que 0. Luego, crea un gráfico de barra apiladas del promedio deweight, por parcela, con valoresmaleversusfemaleapilados por cada parcela.
- En Python, fragmentos de datos pueden ser accedidos usando índices, cortes, encabezados de columnas, y subconjuntos basados en condiciones.
- Python usa indexación base-0, en la cual el primer elemento de una lista, tupla o cualquier otra estructura de datos tiene un índice de 0.
- ‘Pandas’ permite usar procedimientos comunes de exploración de datos como indexación de datos, cortes y creación de subconjuntos basados en condiciones.
Content from Tipos de datos y formatos
Última actualización: 2023-02-07 | Mejora esta página
El formato de columnas y filas individuales afectará el análisis realizado en un dataset leído en Python. Por ejemplo, no se pueden realizar cálculos matemáticos sobre una secuencia de caracteres (datos con formato de texto). Esto puede parecer obvio, sin embargo, a veces en Python los valores numéricos son leídos como secuencias de caracteres. En esta situación, cuando intentas realizar cálculos con datos numéricos sobre datos formateados como secuencias de caracteres, obtienes un error.
Hoja de ruta
Preguntas
- ¿Qué tipos de datos pueden estar contenidos en un DataFrame?
- ¿Por qué es importante el tipo de datos?
Objetivos
- Describir cómo se almacena la información en un DataFrame de Python.
- Examinar la estructura de un DataFrame.
- Modificar el formato de los valores en un DataFrame.
- Describir cómo los tipos de datos afectan a las operaciones.
- Definir, manipular e interconvertir integers y floats en Python.
- Analizar datasets que tienen valores faltantes/nulos (valores NaN).
- Escribir datos manipulados a un archivo.
En esta lección repasaremos maneras de explorar y comprender mejor la estructura y formato de nuestros datos.
Tipos de Datos
La forma en que se almacena la información en un DataFrame u objeto Python afecta a lo que podemos hacer con él y también a los resultados de los cálculos. Hay dos tipos principales de datos que estaremos explorando en esta lección: tipos de datos numéricos y de texto.
Tipos de Datos Numéricos
Los tipos de datos numéricos incluyen enteros
(integer) y números de punto flotante
(float). Un número de punto flotante tiene puntos
decimales incluso si el valor del punto decimal es 0. Por ejemplo: 1.13,
2.0, 1234.345. Si tenemos una columna que contiene tanto enteros como
números de punto flotante, Pandas asignará el tipo de dato
float a toda la columna, de modo tal que los puntos
decimales no se pierdan.
Un integer nunca tendrá un punto decimal. Así que,
si quisiéramos almacenar 1.13 como un entero de tipo
integer se almacenará como 1. Del mismo modo, 1234.345
se almacenará como 1234. A menudo, en Python verás el tipo de dato
Int64 que representa un entero de 64 bits. El 64
simplemente se refiere a la memoria asignada para almacenar datos en
cada celda; eso se refiere a la cantidad de dígitos que puede
efectivamente almacenar cada “celda”. Asignar espacio antes de tiempo
permite a las computadoras optimizar el almacenamiento y hacer más
eficiente el procesamiento.
Tipo de Datos de Texto
En Python, el tipo de datos de texto se conoce como secuencia de caracteres (string). En Pandas se los conoce como objetos (object). Las secuencias de caracteres pueden contener números y / o caracteres. Por ejemplo, una secuencia de caracteres puede ser una palabra, una oración, o varias oraciones. Un objeto Pandas también podría ser un nombre de gráfico como ‘plot1’. Una secuencia de caracteres también puede contener o consistir en números. Por ejemplo, ‘1234’ podría ser almacenado como una secuencia de caracteres. También ‘10.23’ podría ser almacenado como secuencia de caracteres. Sin embargo, ¡las las secuencias de caracteres que contienen números no se pueden utilizar en operaciones matemáticas!
Pandas y Python básico utilizan nombres ligeramente diferentes para los tipos de datos. Más sobre esto en la tabla de abajo:
| Tipo en Pandas | Tipo en Python Nativo | Descripción |
|---|---|---|
| object | string | El dtype más general. Será asignado a tu columna si la columna contiene tipos mixtos (números y secuencias de caracteres). |
| int64 | int | Caracteres numéricos. 64 se refiere a la memoria asignada para almacenar el caracter. |
| float64 | float | Caracteres numéricos con decimales. Si una columna contiene números y NaNs (ver más abajo), Pandas usará float64 por defecto, en caso de que los datos faltantes contengan decimales. |
| datetime64, timedelta[ns] | N/D (ver el módulo datetime en la biblioteca estandar de Python) | Valores destinados a contener datos de tiempo. Mira en estos para experimentos con series de tiempo. |
Comprobando el formato de nuestros datos
Ahora que tenemos una comprensión básica de los tipos de datos
numéricos y de texto, exploremos el formato de los datos de nuestra
encuesta. Estaremos trabajando con el mismo dataset
surveys.csv que hemos usado en lecciones anteriores.
PYTHON
# Ten en cuenta que se usa `pd.read_csv` porque importamos pandas con el alias `pd`
surveys_df = pd.read_csv ("data/surveys.csv")Recuerda que podemos comprobar el tipo de un objeto de la siguiente manera:
OUTPUT: pandas.core.frame.DataFrame
A continuación, veamos la estructura de datos de nuestras encuestas.
En pandas, podemos comprobar el tipo de datos de una columna en un
DataFrame usando la sintaxis
dataFrameName[column_name].dtype:
OUTPUT: dtype('O')
Un tipo ‘O’ solo significa “objeto” que en el mundo de Pandas es una secuencia de caracteres (texto).
OUTPUT: dtype('int64')
El tipo int64 nos dice que Python está almacenando cada
valor dentro de esta columna como un entero de 64 bits. Podemos usar el
comando dat.dtypes para ver el tipo de datos de cada
columna de un DataFrame (todos a la vez).
which returns:
PYTHON
record_id int64
month int64
day int64
year int64
plot_id int64
species_id object
sex object
hindfoot_length float64
weight float64
dtype: objectTen en cuenta que la mayoría de las columnas en nuestros datos de
encuesta son del tipo int64. Esto significa que son enteros
de 64 bits. Pero la columna de peso (weight) es un valor de punto
flotante o float, lo que significa que contiene decimales.
Las columnas species_id y sex son objetos, lo
cual significa que contienen secuencias de caracteres
string.
Trabajando con integers y floats
Así que hemos aprendido que las computadoras almacenan los números de
una de dos maneras: como enteros integer o como números de
punto flotante float. Los integers son los
números que usualmente usamos para contar. Los float
tienen parte fraccionaria (decimal). Consideremos ahora cómo el tipo de
datos puede impactar en las operaciones matemáticas entre nuestros
datos. La suma, la resta, la división y la multiplicación funcionan en
float e integer como es de
esperar.
Si dividimos un integer por otro, obtenemos un float. El resultado en Python 3 es diferente al de Python 2, donde el resultado es un integer (porque Python 2 hace una división entera).
También podemos convertir un número de punto flotante en un entero, o un entero en un número de punto flotante. Ten en cuenta que Python redondea por defecto cuando convierte de float a integer.
Trabajando con los datos de nuestra encuesta
Volviendo a nuestros datos, si lo deseamos, podemos modificar el
formato de los valores dentro de nuestros datos. Por ejemplo, podríamos
convertir el campo record_id a float
PYTHON
# Convertir el campo record_id de integer a float
surveys_df['record_id'] = surveys_df['record_id'].astype('float64')
surveys_df['record_id'].dtypeOUTPUT: dtype('float64')
Desafío - Cambiando tipos
Intenta convertir la columna
plot_ida float usandoA continuación, intenta convertir
weight(peso) en un integer. ¿Qué te dice Pandas? ¿Qué es lo que va mal ahí? Más adelante, hablaremos acerca de algunas soluciones a esto.
Valores de datos faltantes o nulos - NaN
¿Qué ocurrió en en el desafío? Ten en cuenta que esto arroja un error de valor:
ValueError: Cannot convert NA to integer.
Si observamos la columna weight (peso) de los datos de
las encuestas, notamos que hay valores NaN (Not
a Number) (no es número). Los valores
**NaN ** son valores que no están definidos y que no se pueden
representar matemáticamente. Pandas, por ejemplo, leerá como NaN
aquellas celdas vacías de una hoja CSV o Excel. Los valores NaN tienen
algunas propiedades deseables: si tuviéramos que promediar la columna
weight (peso) sin reemplazar los valores NaN, Python sabría
saltarse las celdas vacías.
Tratar con valores de datos faltantes siempre es un desafío. A veces es dificil saber por qué faltan valores. ¿Fue debido a un error de entrada de datos? ¿O son datos que alguien no pudo recoger? ¿Debe considerarse el valor como 0? Para tomar buenas decisiones, necesitamos saber qué representan los valores faltantes del dataset. Si tenemos suerte, tendremos algunos metadatos que nos dirán más acerca de cómo fueron manejados los valores nulos.
Por ejemplo, en algunas disciplinas, como el sensado remoto, los valores de datos faltantes suelen definirse como -9999. Tener un montón de valores -9999 en tus datos podría realmente alterar los cálculos numéricos. A menudo, en las hojas de cálculo, las celdas se dejan vacías cuando no hay datos disponibles. Por defecto, Pandas reemplazará esos valores nulos con NaN. Sin embargo, es una buena práctica adquirir el hábito de marcar intencionalmente aquellas celdas que no tienen datos con un valor que represente “sin datos”! De esa manera, en el futuro, no habrá preguntas cuando tu (o alguna otra persona) explore los datos.
¿Dónde están los NaN’s?
Exploremos un poco más los valores NaN en nuestros datos. Usando las herramientas que hemos aprendido en la lección 02, podemos averiguar cuántas filas contienen valores NaN en la columna weight (peso). También, partiendo de nuestros datos, podemos crear un nuevo subconjunto que contenga solamente aquellas filas con peso mayor a cero (es decir, seleccionar valores significativos de peso):
PYTHON
len(surveys_df[pd.isnull(surveys_df.weight)])
# How many rows have weight values?
len(surveys_df[surveys_df.weight> 0])Usando el método .fillna () podemos reemplazar todos los
valores NaN por ceros (después de hacer una copia de
los datos de modo tal de no perder nuestro trabajo):
PYTHON
df1 = surveys_df.copy()
# Completar todos los valores NaN con ceros
df1['weight'] = df1['weight'].fillna(0)Sin embargo, NaN y cero arrojan diferentes resultados en el análisis. El valor promedio resulta diferente cuando los valores NaN se reemplazan con cero, comparando cuando los valores de NaN son descartados o ignorados.
Podemos completar los valores NaN con cualquier valor que elijamos. El código de abajo completa todos los Valores NaN con un promedio de los pesos.
También podríamos elegir crear un subconjunto de datos, manteniendo solamente aquellas filas que no contienen valores NaN.
La clave es tomar decisiones conscientes acerca de cómo administrar los datos faltantes. Aquí es donde pensamos cómo se utilizarán nuestros datos y cómo estos valores afectarán las conclusiones científicas que se obtengan de los datos.
Python nos brinda todas las herramientas que necesitamos para dar cuenta de estos problemas. Solo debemos ser cautelosos acerca de cómo nuestras decisiones impactan en los resultados científicos.
Desafío - Contando
Cuenta el número de valores perdidos por columna. Sugerencia: el
método .count() te proporciona el número de observaciones
que no son NA por columna. Examina el método .isnull().
Escribiendo datos a CSV
Hemos aprendido a manipular datos para obtener los resultados deseados. Pero también hemos discutido acerca de mantener los datos que han sido manipulados separados de los datos sin procesar. Algo que podríamos estar interesados en hacer es trabajar solo con las columnas que tienen datos completos. Primero, recarguemos los datos para no mezclar todas nuestras manipulaciones anteriores.
A continuación, vamos a eliminar todas las filas que contienen
valores nulos. Usaremos el comando dropna. De forma
predeterminada, dropna elimina las columnas que contienen
valores nulos incluso para una sola fila.
Si ahora escribes df_na, deberías observar que el
DataFrame resultante tiene 30676 filas y 9 columnas,
mucho menos que las 35549 filas originales.
Ahora podemos usar el comando to_csv para exportar un
DataFrame a formato CSV. Ten en cuenta que el código
que se muestra a continuación por defector guardará los datos en el
directorio de trabajo en el que estamos parados. Podemos guardarlo en
otra carpeta agregando el nombre de la carpeta y una barra inclinada
antes del nombre del archivo:
df.to_csv('foldername/out.csv'). Usamos
index = False para que Pandas no incluya el número de
índice para cada fila.
Usaremos este archivo de datos más adelante en el taller. Revisa tu directorio de trabajo para asegurarte de que el CSV se haya guardado correctamente y que puedas abrirlo. Si lo deseas, intenta recuperarlo con Python para asegurarte de que se importa correctamente.
Resumen
Hemos aprendido:
- Cómo explorar los tipos de dato de las colummnas de un DataFrame
- Cómo cambiar el tipo de dato
- Qué son los valores NaN, cómo deberían representarse, y lo que eso significa para tu trabajo
- Cómo reemplazar los valores NaN si así lo quisieras
- Como usar
to_csvpara guardar en un archivo los datos manipulados.
- Pandas usa otros nombres para tipos de datos que Python, por
ejemplo:
objectpara datos textuales. - Una columna en un DataFrame sólo puede tener un tipo de datos.
- El tipo de datos de la columna de un DataFrame puede ser comprobado
usando
dtype. - Es necesario tomar decisiones conscientes sobre cómo manejar los datos faltantes.
- Un DataFrame puede ser guardado en un archivo CSV usando la función
to_csv.
Content from Combinando DataFrames con Pandas
Última actualización: 2023-02-07 | Mejora esta página
En muchas situations del “mundo real”, los datos que queremos usar
proceden de múltiples archivos. Frecuentemente necesitamos combinar
estos archivos en un uniquo DataFrame para analizar los
datos. El paquete pandas proporciona varios
métodos de combinar DataFrames incluyendo
merge y concat.
Hoja de ruta
Preguntas
- ¿Puedo trabajar con datos de diferentes fuentes?
- ¿Cómo puedo combinar datos de diferentes datasets?
Objetivos
- Combinar datos de varios diferentes archivos en un único DataFrame
usando
mergeyconcat. - Combinar dos DataFrames usando un ID único encontrado en ambos DataFrames.
- Unir DataFrames usando campos comunes (unión por claves).
Para trabajar en los ejemplos abajo, necesitamos primero cargar los archivos de species y surveys dentro de pandas DataFrames. En Python:
PYTHON
import pandas as pd
surveys_df = pd.read_csv("data/surveys.csv",
keep_default_na=False, na_values=[""])
surveys_df
record_id month day year plot species sex hindfoot_length weight
0 1 7 16 1977 2 NA M 32 NaN
1 2 7 16 1977 3 NA M 33 NaN
2 3 7 16 1977 2 DM F 37 NaN
3 4 7 16 1977 7 DM M 36 NaN
4 5 7 16 1977 3 DM M 35 NaN
... ... ... ... ... ... ... ... ... ...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[35549 rows x 9 columns]
species_df = pd.read_csv("data/species.csv",
keep_default_na=False, na_values=[""])
species_df
species_id genus species taxa
0 AB Amphispiza bilineata Bird
1 AH Ammospermophilus harrisi Rodent
2 AS Ammodramus savannarum Bird
3 BA Baiomys taylori Rodent
4 CB Campylorhynchus brunneicapillus Bird
.. ... ... ... ...
49 UP Pipilo sp. Bird
50 UR Rodent sp. Rodent
51 US Sparrow sp. Bird
52 ZL Zonotrichia leucophrys Bird
53 ZM Zenaida macroura Bird
[54 rows x 4 columns]Ten en cuenta que el método read_csv que usamos puede
tomar opciones adicionales que no hemos usado anteriormente. Muchas
funciones en Python tienen un conjunto de opciones que
se pueden ser definidas por el usuario si es necesario. En este caso,
hemos indicado a pandas que asigne valores vacíos en
nuestro CSV como NaN
keep_default_na=False, na_values=[""]. Explora
sobre todas las optciones de read_csv a través de este
enlace.
Concatenando DataFrames
Podemos usar la función concat en pandas para agregar
columnas o filas de un DataFrame a otro. Tomemos dos
subconjuntos de nuestros datos para ver cómo esto trabaja.
PYTHON
# Lee las primeras 10 líneas de la tabla de encuestas.
survey_sub = surveys_df.head(10)
# Agarra las últimas 10 filas
survey_sub_last10 = surveys_df.tail(10)
# Restablecer los valores de índice a la segunda __DataFrame__ adjunta correctamente
survey_sub_last10=survey_sub_last10.reset_index(drop=True)
# drop=True opción evita agregar una nueva columna de índice con valores de índice antiguosCuando concatenamos DataFrames, necesitamos
especificar el eje. axis=0 dice pandas para apilar el
segundo DataFrame debajo del primero. Será
automáticamente detecta si los nombres de las columnas son iguales y se
apilarán en consecuencia. axis=1 apilará las columnas en el
segundo DataFrame a la DERECHA del primer
DataFrame. Para apilar los datos verticalmente,
necesitamos asegurarnos de que tenemos las mismas columnas y el formato
de columna asociado en los dos datasets. Cuando apilamos
horizontalmente, queremos asegurarnos de que lo que estamos haciendo
tiene sentido (es decir, los datos son relacionados de alguna
manera).
PYTHON
# Apilar los __DataFrames__ uno encima del otro
vertical_stack = pd.concat([survey_sub, survey_sub_last10], axis=0)
# Coloque los __DataFrames__ de lado a lado
horizontal_stack = pd.concat([survey_sub, survey_sub_last10], axis=1)Valores de índice de fila y Concat
¿Dale una ojeada al vertical_stack
DataFrame? ¿Notaste algo inusual? Los índices de fila
para los dos data frames survey_sub
ysurvey_sub_last10 se han repetido. Podemos reindexar el
nuevo data frame usando el método reset_index().
Escribiendo datos a CSV
Podemos usar el comando to_csv para exportar un
DataFrame en formato CSV. Nota que el código a
continuación guardará los datos por defecto en el directorio de trabajo
corriente. Podemos guárdelo en un directorio diferente agregando el
nombre de la carpeta y una barra al archivo
vertical_stack.to_csv ('foldername/out.csv'). Usamos el
‘índice = Falso’ para que pandas no incluye el número de índice para
cada línea.
Revise su directorio de trabajo para asegurarse de que el CSV se haya escrito correctamente, y que puedas abrirlo! Si quieres, intenta subirlo de vuelta a Python para asegurarte se importa correctamente.
PYTHON
# Para los memes lee nuestro archivo en Python y asegúrese de que todo se vea bien.
new_output = pd.read_csv('data_output/out.csv', keep_default_na=False, na_values=[""])Challenge - Combine Data
En la carpeta de datos, hay dos archivos de datos de encuestas:
survey2001.csv y survey2002.csv. Lee los datos
en Python y combina los archivos para hacer un
DataFrame nuevo. Crea una gráfica del peso promedio de
la parcela, plot_id, por año agrupada por sexo. Exporta tus
resultados como CSV y asegúrate de que se lean correctamente en
Python.
Unión de los DataFrames
Cuando concatenamos nuestros DataFrames, simplemente los agregamos unos a otros - apilándolos verticalmente o lado a lado. Otra forma de combinar DataFrames es usar columnas en cada dataset que contienen valores comunes (un ID única común). Combinando DataFrames utilizando un campo común se llama “joining” (unión). Las columnas que contienen los valores comunes se llaman “join key(s)” (claves de unión). Muchas veces uniendo DataFrames de esta manera es útil cuando un DataFrame es una “lookup table” (tabla de búsqueda) que contiene datos adicionales que queremos incluir en el otro DataFrame.
NOTA: Este proceso de unir tablas es similar a lo que hacemos con las tablas en una base de datos SQL.
Por ejemplo, el archivo species.csv con el que hemos
estado trabajando es una tabla de búsqueda. Esta tabla contiene el
código de género, especie y taxa para 55 especies. El código de la
especie es único para cada línea. Estas especies se identifican en los
datos de nuestra encuesta y también utilizan el código único de
especies. En lugar de agregar 3 columnas más para el género, las
especies y los taxones a cada una de las 35,549 líneas de la tabla de
datos de la encuesta, podemos mantener la tabla más corta con la
información de la especie. Cuando queremos accesar esa información,
podemos crear una consulta que une las columnas adicionales de
información a los datos de la encuesta.
Almacenar los datos de esta manera tiene muchos beneficios, entre ellos:
Asegura la consistencia en la ortografía de los atributos de las especies (género, especie y taxones) dado que cada especie solo se ingresa una vez. ¡Imagine las posibilidades de errores de ortografía al ingresar el género y las especies miles de veces!
También nos facilita realizar cambios en la información de la especie una vez sin tener que encontrar cada instancia en los datos de la encuesta.
Optimiza el tamaño de nuestros datos.
Unión de Dos DataFrames
Para comprender mejor las uniones, tomemos las primeras 10 líneas de
nuestros datos como un subconjunto con para trabajar. Usaremos el método
.head para hacer esto. También vamos a importar un
subconjunto de la tabla de especies.
PYTHON
# Lee las primeras 10 líneas de la tabla de encuestas.
survey_sub = surveys_df.head(10)
# Importe un penqueño subconjunto de los datos de especies diseñados para esta parte de la lección.
# Esa archivado en la carpeta de datos.
species_sub = pd.read_csv('data/speciesSubset.csv', keep_default_na=False, na_values=[""])En este ejemplo, species_sub es la tabla de búsqueda que
contiene género, especie y nombres de taxa que queremos unir con los
datos en survey_sub para producir un nuevo
DataFrame que contiene todas las columnas de
species_df y survey_df.
Identifying join keys
Para identificar las claves de combinación adecuadas, primero necesitamos saber cuáles campos son compartidos entre los archivos (DataFrames). Podríamos inspeccionar los dos DataFrames para identificar estas columnas. Si tenemos suerte, los dos DataFrames tendrán columnas con el mismo nombre que también contienen los mismos datos. Si somos menos afortunados, necesitamos identificar una columna (con nombre diferente) en cada DataFrame que contiene la misma información.
PYTHON
>>> species_sub.columns
Index([u'species_id', u'genus', u'species', u'taxa'], dtype='object')
>>> survey_sub.columns
Index([u'record_id', u'month', u'day', u'year', u'plot_id', u'species_id',
u'sex', u'hindfoot_length', u'weight'], dtype='object')En nuestro ejemplo, la clave de unión es la columna que contiene el
identificador de especie de dos letras, que se llama
species_id.
Ahora que conocemos los campos con los atributos de ID de especies comunes en cada DataFrame, estamos casi listos para unir nuestros datos. Sin embargo, porque hay diferentes tipos de uniones, también debemos decidir qué tipo de unión tiene sentido para nuestro análisis.
Uniones internas
El tipo más común de unión se llama inner join (unión interna). Una combinación interna combina dos DataFrames basados en una clave de unión y devuelve un nuevo DataFrame que contiene solo aquellas filas que tienen valores coincidentes entre los dos DataFrames originales.
Las uniones internas producen un DataFrame que contiene solo filas donde el valor que es el subjecto de la unión existe en las dos tablas. Un ejemplo de una unión interna, adaptado de esta página se encuentra a continuación:
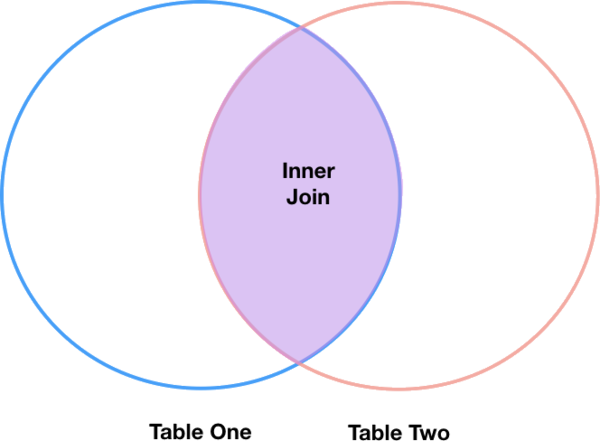
La función en pandas para realizar uniones se llama
merge y una unión interna es la opción por defecto:
PYTHON
merged_inner = pd.merge(left=survey_sub,right=species_sub, left_on='species_id', right_on='species_id')
# En este caso, `species_id` es el único nombre de columna en los dos __DataFrames__, entonces si omitimos
# los argumentos `left_on` y `right_on` todavía obtendríamos el mismo resultado
# ¿Cuál es el tamaño de los datos en el resultado?
merged_inner.shape
merged_innerOUTPUT:
SALIDA
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 8 7 16 1977 1 DM M 37
6 9 7 16 1977 1 DM F 34
7 7 7 16 1977 2 PE F NaN
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN Dipodomys merriami Rodent
6 NaN Dipodomys merriami Rodent
7 NaN Peromyscus eremicus RodentEl resultado de una unión interna de survey_sub y
species_sub es un nuevo DataFrame que
contiene el conjunto combinado de columnas de survey_sub y
species_sub. Solo contiene filas que tienen
códigos de dos letras de especies que son iguales en el
survey_sub y el species_sub
DataFrames. En otras palabras, si una fila en
survey_sub tiene un valor de species_id que
no aparece en la species_id columna de
species, no será incluirá en el DataFrame
devuelto por una unión interna. Del mismo modo, si una fila en
species_sub tiene un valor de species_id que
no aparece en la columna species_id de
survey_sub, esa fila no será incluida en el
DataFrame devuelto por una unión interna.
Los dos DataFrames a los que queremos unir se pasan
a la función merge usando el argumento de left
y right. El argumento left_on = 'species' le
dice a merge que use la columna species_id
como la clave de unión de survey_sub (el left
DataFrame). De manera similar, el argumento
right_on = 'species_id' le dice a merge que
use la columna species_id como la clave de unión
despecies_sub (el right
DataFrame). Para uniones internas, el orden de los
argumentos left yright no importa.
El resultado merged_inner DataFrame
contiene todas las columnas desurvey_sub (ID de registro,
mes, día, etc.), así como todas las columnas de species_sub
(especies_id, género, especie y taxa).
Date cuenta que merged_inner tiene menos filas que
survey_sub. Esto es una indicación de que había filas en
survey_df con valor(es) para species_id que no
existen como valor(es) para species_id en
species_df.
Unión izquierda
¿Qué pasa si queremos agregar información de species_sub
a survey_sub sin perdiendo información de
survey_sub? En este caso, utilizamos un diferente tipo de
unión llamada “left outer join (unión externa
izquierda)”, or a “left join (unión izquierda)”.
Como una combinación interna, una unión izquierda utiliza las claves
de unión para combinar dos DataFrames. Diferente a una
unión interna, una unión izquierda devolverá todas las filas
del left DataFrame, hasta aquellas filas
cuyas claves de unión no tienen valores en el right
DataFrame. Filas en el left
DataFrame que faltan valores para las clave(s) de unión
en el right DataFrame simplemente tendrán
valores nulos (es decir, NaN o Ninguno) para las columnas en el
resultante DataFrame unido.
Nota: una unión izquierda todavía descartará las filas del
right DataFrame que no tienen valores para
la(s) clave(s) de unión en el left
DataFrame.

Una unión izquierda se realiza en pandas llamando a la misma función
merge utilizada para unión interna, pero usando el
argumento how = 'left':
PYTHON
merged_left = pd.merge(left=survey_sub,right=species_sub, how='left', left_on='species_id', right_on='species_id')
merged_left
**OUTPUT:**
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 6 7 16 1977 1 PF M 14
6 7 7 16 1977 2 PE F NaN
7 8 7 16 1977 1 DM M 37
8 9 7 16 1977 1 DM F 34
9 10 7 16 1977 6 PF F 20
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN NaN NaN NaN
6 NaN Peromyscus eremicus Rodent
7 NaN Dipodomys merriami Rodent
8 NaN Dipodomys merriami Rodent
9 NaN NaN NaN NaNEl resultado DataFrame de una unión izquierda
(merged_left) se parece mucho al resultado
DataFrame de una unión interna
(merged_inner) en términos de las columnas que contiene.
Sin embargo, a diferencia de merged_inner,
merged_left contiene el mismo número de
filas como el DataFrame original
survey_sub. Cuando inspeccionamos merged_left,
encontramos que hay filas donde la información debería haber venido de
species_sub (es decir,species_id,
genus ytaxa) hace falta (contienen valores de
NaN):
PYTHON
merged_left[ pd.isnull(merged_left.genus) ]
**OUTPUT:**
record_id month day year plot_id species_id sex hindfoot_length \
5 6 7 16 1977 1 PF M 14
9 10 7 16 1977 6 PF F 20
weight genus species taxa
5 NaN NaN NaN NaN
9 NaN NaN NaN NaNEstas filas son aquellas en las que el valor de
species_id desurvey_sub (en este caso,
PF) no ocurre enspecies_sub.
Otros tipos de unión
La función merge de pandas admite otros dos tipos de
unión:
-
Right (outer) join unión derecha (exterior): se
invoca al pasar
how = 'right'como argumento. Similar a una unión izquierda, excepto que se guardan todas las filas delrightDataFrame, mientras que las filas delleftDataFrame sin coincidir con los valores de las claves de unión son descartadas. -
Full (outer) join unión completa (externa): se
invoca al pasar
how = 'outer'como argumento. Este tipo de unión devuelve todas las combinaciones de filas de los dos DataFrames; es decir., el DataFrame resultante estaráNaNdonde faltan datos en uno de los DataFrames. Este tipo de unión es muy raramente utilizado.
Desafíos Finales
Desafío - Distribuciones
Cree un nuevo DataFrame uniendo los contenidos de
survey.csv y Tablas species.csv. Luego calcula
y crea un gráfico de la distribución de:
- taxa por parcela
- taxa por sexo por parcela
Desafío - Índice de Diversidad
- En la carpeta de datos, hay un gráfico
CSVque contiene información sobre el tipo asociado con cada parcela. Usa esos datos para resumir el número de parcelas por tipo de parcela. - Calcula un índice de diversidad de su elección para control vs parcelas de rodamiento de roedores El índice debe considerar tanto la abundancia de especies como el número de especies. Puedes optar por utilizar el simple índice de biodiversidad descrito aquí que calcula la diversidad como:
el número de especies en la parcela / el número total de individuos en la parcela = índice de biodiversidad.
- Podemos usar la función
concaten pandas para agregar columnas o filas de un DataFrame a otro. - Se pueden combinar DataFrames en base a columnas en cada dataset que contienen valores comunes (un ID única común), esta combinación utilizando un campo común se llama “joining” (unión).
- Es posible realizar distintos tipos de uniones: interna cuyo resultado solamente tiene las filas donde coinciden las columnas clave en ambos DataFrame, externa hacia la izquierda o la derecha, si queremos conservar las filas del DataFrame de origen o destino respectivamente, o una unión externa completa, con filas para todas las combinaciones de las columnas clave.
Content from Flujos de trabajo y automatización
Última actualización: 2023-02-07 | Mejora esta página
Hasta este momento, hemos usado Python y la librería Pandas para explorar y manipular datasets a mano, tal y como lo haríamos en una planilla de cálculo. Sin embargo la belleza de usar un lenguaje de programación como Python viene de la posibilidad de automatizar el procesamiento de los datos a través del uso de bucles y funciones.
Hoja de ruta
Preguntas
- ¿Puedo automatizar operaciones en Python?
- ¿Qué son las función y por qué debería usarlas?
Objetivos
- Describir por qué se usan los bucles en Python.
- Usar bucles for para automatizar el análisis de datos.
- Escribir nombres de archivo únicos en Python.
- Construir código reusable en Python.
- Escribir funciones usando condicionales (if, then, else).
Bucles for
Los bucles nos permiten repetir un flujo de trabajo (o una serie de acciones) cierto número dado de veces o mientras una condición es cierta. Podríamos usar un bucle para procesar automáticamente la información que está contenida en múltiples archivos (valores diarios con un archivo por año, por ejemplo). Los bucles nos alivian nuestra tarea al hacer tareas repetitivas sin que tengamos que involucrarnos directamente, y hace menos probable que introduzcamos errores al equivocarnos mientras procesamos cada archivo manualmente.
Escribamos un bucle for sencillo que simule lo que un niño podría ver durante una visita al zoológico:
SALIDA
['lion', 'tiger', 'crocodile', 'vulture', 'hippo']SALIDA
lion
tiger
crocodile
vulture
hippoLa línea que define el bucle debe comenzar con un for y terminar con el caracter dos puntos, y el cuerpo del bucle debe estar indentado.
Eh este ejemplo, creature es la variable del bucle que
toma el valor de la siguiente entrada en animals cada vez
que el bucle hace una iteración. Podemos darle a la variable del bucle
el nombre que querramos. Después que se termina el bucle, la variable
del bucle continuará existiendo y tendrá el valor de la última entrada
en la colección.
SALIDA
SALIDA
The loop variable is now: hippoAcá no le estamos pidiendo a Python que imprima el valor de la
variable del bucle, pero el bucle todavía corre y el valor de
creature cambia en cada iteración. La palabra clave
pass en el cuerpo del bucle significa solamente “no hagas
nada”.
Desafío - Bucles
¿Qué pasa si no incluimos la palabra clave
pass?Reescribe el bucle de tal forma que los animales estén separados por comas y no por una línea nueva. (Pista: Puedes concatenar cadenas de caracteres usando el signo más. Por ejemplo,
print(string1 + string2)resulta en ‘string1string2’).
Automatizando el procesamiento de datos usando bucles For
El archivo que hemos estado usando hasta este momento,
surveys.csv, contiene 25 años de información y es muy
grande. Nos encantaría separar esta información por años y guardar un
archivo por cada año.
Comencemos por crear un nuevo directorio en nuestra carpeta
data para guardar todos estos archivos usando el módulo
os
El comando os.mkdir es equivalente a escribir
mkdir en la terminal. Solo para estar seguros, podemos
verificar que nuestro nuevo directorio fue creado en la carpeta
data:
SALIDA
['plots.csv',
'portal_mammals.sqlite',
'species.csv',
'survey2001.csv',
'survey2002.csv',
'surveys.csv',
'surveys2002_temp.csv',
'yearly_files']El comando os.listdir es equivalente a usar
ls en la terminal.
En episodios anteriores, vimos cómo usar la librería Pandas para cargar en memoria, a través de DataFrame, información sobre las especies; vimos cómo seleccionar un subconjunto de esos datos usando ciertos criterios, y vimos también cómo escribir esa información en un archivo CSV. Escribamos un script que realiza esos tres pasos en secuencia para el año 2002:
PYTHON
import pandas as pd
# Cargamos los datos en un DataFrame
surveys_df = pd.read_csv('data/surveys.csv')
# Seleccionamos solo los datos del año 2002
surveys2002 = surveys_df[surveys_df.year == 2002]
# Escribimos el nuevo DataFrame en un archivo CSV
surveys2002.to_csv('data/yearly_files/surveys2002.csv')Para crear los archivos con los datos anuales, podemos repetir estos últimos dos comandos una y otra vez, una vez por cada año de información. Sin embargo, repetir código no es ni elegante ni práctico, y hace muy probable que introduzcamos errores en nuestro código. Queremos convertir lo que acabamos de escribir en un bucle que repita estos últimos dos comandos para cada año en nuestro dataset.
Comencemos con un bucle que solamente imprima los nombres de los archivos que queremos crear - El dataset que estamos usando va desde 1977 hasta 2002, y vamos a crear un archivo por separado para cada año. Listar los nombres de los archivos es una buena estrategia, porque así podemos confirmar que nuestro bucle se está comportando como esperamos.
Hemos visto que podemos iterar sobre una lista de elementos, entonces necesitamos una lista de años sobre la cual iterar. Podemos obtener los años en nuestro DataFrame con:
SALIDA
0 1977
1 1977
2 1977
3 1977
...
35545 2002
35546 2002
35547 2002
35548 2002pero queremos solamente años únicos, y esto lo podemos obtener usando
el método unique que ya hemos visto.
SALIDA
array([1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987,
1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998,
1999, 2000, 2001, 2002], dtype=int64)Escribiendo esto en un bucle for obtenemos
PYTHON
for year in surveys_df['year'].unique():
filename='data/yearly_files/surveys' + str(year) + '.csv'
print(filename)SALIDA
data/yearly_files/surveys1977.csv
data/yearly_files/surveys1978.csv
data/yearly_files/surveys1979.csv
data/yearly_files/surveys1980.csv
data/yearly_files/surveys1981.csv
data/yearly_files/surveys1982.csv
data/yearly_files/surveys1983.csv
data/yearly_files/surveys1984.csv
data/yearly_files/surveys1985.csv
data/yearly_files/surveys1986.csv
data/yearly_files/surveys1987.csv
data/yearly_files/surveys1988.csv
data/yearly_files/surveys1989.csv
data/yearly_files/surveys1990.csv
data/yearly_files/surveys1991.csv
data/yearly_files/surveys1992.csv
data/yearly_files/surveys1993.csv
data/yearly_files/surveys1994.csv
data/yearly_files/surveys1995.csv
data/yearly_files/surveys1996.csv
data/yearly_files/surveys1997.csv
data/yearly_files/surveys1998.csv
data/yearly_files/surveys1999.csv
data/yearly_files/surveys2000.csv
data/yearly_files/surveys2001.csv
data/yearly_files/surveys2002.csvAhora podemos agregar el resto de pasos que necesitamos para crear archivos separados:
PYTHON
# Load the data into a DataFrame
surveys_df = pd.read_csv('data/surveys.csv')
for year in surveys_df['year'].unique():
# Select data for the year
surveys_year = surveys_df[surveys_df.year == year]
# Write the new DataFrame to a CSV file
filename = 'data/yearly_files/surveys' + str(year) + '.csv'
surveys_year.to_csv(filename)Mira dentro del directorio yearly_files y verifica un
par de los archivos que acabaste de crear para confirmar que todo
funcionó como esperabas.
Escribiendo nombres de archivo únicos
Nota que en el código anterior creamos un nombre de archivo único para cada año.
Descompongamos las partes de este nombre:
- La primera parte es simplemente un texto que especifica el
directorio en el que vamos a guardar nuestro archivo
(data/yearly_files/) y la primera parte del nombre del archivo
(surveys):
'data/yearly_files/surveys' - Podemos concatenar esto con el valor de una variable, en este caso
year, al usar el signo más y la variable que le queremos añadir al nombre del archivo:+ str(year) - Por último añadimos la extensión del archivo usando otra cadena de
caracteres:
+ '.csv'
Nota que usamos comillas sencillas para añadir las cadenas de
caracteres y que la variable no está entre comillas. Este código produce
la cadena de caracteres data/yearly_files/surveys2002.csv
que contiene tanto el path como el nombre del
archivo.
Desafío - Modificando bucles
Algunas de las encuestas que guardaste tienen datos faltantes (tienen valores nulos que salen como
NaN- No es un número (en inglés) - en los DataFrames y no salen en los archivos de texto). Modifica el bucle for para que las entradas que tengan valores nulos no sean incluidas en los archivos anuales.Supongamos que solo quieres revisar los datos cada cierto múltiplo de años. ¿Cómo modificarías el bucle para generar un archivo de datos cada cinco años comenzando desde 1977?
En vez de separar la información por años, un colega tuyo quiere hacer el análisis separando por especies. ¿Cómo escribirías un único archivo CSV por cada especie?
Construyendo código modular y reusable usando funciones
Supón que separar archivos enormes en archivos anuales individuales es una tarea que tenemos que realizar frecuentemente. Podríamos escribir un bucle for como el que hicimos arriba cada vez que lo necesitemos, pero esto tomaría mucho tiempo y podría introducir errores en el código. Una solución más elegante sería crear una herramienta reusable que realice esta tarea con el mínimo esfuerzo del usuario. Para hacerlo, vamos a convertir el código que ya escribimos en una función.
Las funciones son piezas de código reusable y autónomo que pueden ser llamadas mediante un solo comando. Están diseñadas para aceptar argumentos como entrada y retornar valores, pero no necesitan hacerlo necesariamente. Las variables declaradas adentro de las funciones solo existen mientras la función se está ejecutando, y si una variable adentro de una función (una variable local) tiene el mismo nombre de otra variable en alguna parte del código, la variable local no sobrescribe a la otra.
Todo método usado en Python (como por ejemplo print) es
una función, y las librerías que importamos (pandas, por
ejemplo) son una colección de funciones. Solo usaremos las funciones que
están contenidas en el mismo código que las usan, pero es sencillo
también escribir funciones que puedan ser usadas por programas
diferentes.
Las funciones se declaran usando la siguiente estructura general:
PYTHON
def this_is_the_function_name(input_argument1, input_argument2):
# El cuerpo de la función está indentado
# Esta función imprime los dos argumentos en pantalla
print('The function arguments are:', input_argument1, input_argument2, '(this is done inside the function!)')
# And returns their product
return input_argument1 * input_argument2La declaración de la función comienza con la palabra clave
def, seguida del nombre de la función y los argumentos
entre paréntesis, y termina con un dos puntos. El cuerpo de la función
está indentado justo como ocurría con los bucles. Si la función retorna
algo al ser llamada, entonces incluimos la palabra clave
return al final.
Así es como llamamos a la función:
SALIDA
The function arguments are: 2 5 (this is done inside the function!)SALIDA
Their product is: 10 (this is done outside the function!)Desafío - Funciones
- Cambia los valores de los argumentos en la función y mira su salida.
- Intenta llamar a la función usando la cantidad equivocada de
argumentos (es decir, diferente de 2) o sin asignar la llamada de la
función a una variable (sin poner
product_of_inputs =). - Declara una variable dentro de una función y prueba a encontrar en dónde existe (Pista: ¿puedes imprimirla desde fuera de la función?)
- Explora qué sucede cuando una variable tiene el mismo nombre adentro y afuera de la función. ¿Qué le ocurre a la variable global cuando cambias el valor de la variable local?
Ahora podemos convertir el código para guardar archivos con datos anuales en una función. Hay muchas “partes” de este código que podemos convertir en funciones, y podríamos inclusive crear funciones que llaman a otras funciones adentro de ellas. Comencemos escribiendo una función que separa los datos para un año y los guarda en un archivo:
PYTHON
def one_year_csv_writer(this_year, all_data):
"""
Escribe un archivo csv con los datos para un año dado.
this_year --- el año del que vamos a extraer los datos
all_data --- DataFrame con datos de múltiples años
"""
# Seleccionamos los datos para el año
surveys_year = all_data[all_data.year == this_year]
# Escribimos el nuevo DataFrame a un archivo csv
filename = 'data/yearly_files/function_surveys' + str(this_year) + '.csv'
surveys_year.to_csv(filename)El texto que está entre los dos grupos de tres comillas dobles se llama el docstring y contiene la documentación de la función. No hace nada al ejecutar la función y por tanto no es necesario, pero es una excelente práctica incluir docstrings para recordar y explicar qué hace el código. Los docstrings en las funciones también se vuelven parte de la documentación “oficial”:
Cambiamos el nombre del archivo CSV para diferenciarlo del que
escribimos anteriormente. Busca en el directorio
yearly_files el archivo que creamos. ¿Hizo la función lo
que esperabas que hiciera?
Sin embargo, lo que nos encantaría hacer es crear archivos para
múltiples años sin tener que pedirlos uno a uno. Escribamos otra función
que reemplace el bucle for simplemente iterando a
través de la secuencia de años y llamando repetidamente a la función que
acabamos de escribir, one_year_csv_writer:
PYTHON
def yearly_data_csv_writer(start_year, end_year, all_data):
"""
Escribe archivos CSV separados para cada año de datos.
start_year --- el primer año de datos que queremos
end_year --- el último año de datos que queremos
all_data --- DataFrame con datos de varios años
"""
# "end_year" es el último año que queremos extraer, entonces iteramos hasta end_year+1
for year in range(start_year, end_year+1):
one_year_csv_writer(year, all_data)Como la gente esperará naturalmente que el año final
(end_year) sea el último, el bucle for
adentro de la función termina en end_year + 1. Al escribir
el bucle entero en la función, hemos hecho una herramienta reusable para
cuando necesitemos partir un archivo de datos grande en archivos
anuales. Como podemos especificar el primer y el último año para los
cuales queremos crear archivos, podemos inclusive usar esta función para
crear archivos para un subconjunto de los años disponibles. Así
llamaríamos la función:
PYTHON
# Cargamos los datos en un DataFrame
surveys_df = pd.read_csv('data/surveys.csv')
# Creamos los archivos CSV
yearly_data_csv_writer(1977, 2002, surveys_df)¡TEN CUIDADO! Si estás usando Jupyter Notebooks y estás modicando la función, DEBES volver a ejecutar la celda para que la función cambiada esté disponible para el resto del código. Nada cambiará visualmente cuando hagas esto, porque definir una función sin ejecutarla no produce ninguna salida. Toda otra celda que use la función (ahora cambiada) también tendrá que ser re-ejecutada para cambiar su salida.
Challenge- Más funciones
- Añade dos argumentos a las funciones que escribimos que tomen el path del directorio donde los archivos serán escritos y el root del nombre del archivo. Crea un nuevo conjunto de archivos con un nombre diferente en un directorio diferente.
- ¿Cómo podrías usar la función
yearly_data_csv_writerpara crear un archivo CSV para solo un año? (Pista: piensa sobre la sintaxis pararange) - Haz que las funciones retornen una lista de los archivos que
escribieron. Hay muchas formas en las que puedes hacer esto (¡y deberías
intentarlas todas!): cualquiera de las dos funciones podría imprimir
algo en pantalla, cualquiera podría usar
returnpara retornar números o cadenas de caracteres cada vez que se llaman, o podrías hacer una combinación de estas dos estrategias. Podrías también intentar usar la libreríaospara listar los contenidos de directorios. - Explora qué sucede cuando las variables son declaradas dentro de cada una de las funciones versus en el cuerpo principal de tu código (lo que está sin indentar). ¿Cuál es el alcance de las variables (es decir, dónde son visibles)?, ¿qué ocurre si tienen el mismo nombre pero valores diferentes?
Las funciones que escribimos exigen que les demos un valor para cada
argumento. Idealmente, nos gustaría que estas funciones fuesen tan
flexibles e independientes como fuera posible. Modifiquemos la función
yearly_data_csv_writer para que start_year y
end_year sean por defecto el rango completo de los datos si
no son dados por el usuario. Se le pueden asignar a los argumentos
valores por defecto usando el signo igual a la hora de declarar la
función. Todos los argumentos en la función que no tengan un valor por
defecto (como aquí all_data) serán argumentos requeridos y
DEBERÁN ir antes de los argumentos que tengan valores por defecto (y que
son opcionales al llamar la función).
PYTHON
def yearly_data_arg_test(all_data, start_year = 1977, end_year = 2002):
"""
Modificación de yearly_data_csv_writer para probar argumentos con valores
por defecto!
start_year --- el primer año de datos que queremos --- por defecto: 1977
end_year --- el último año de datos que queremos --- por defecto: 2002
all_data --- DataFrame con datos de varios años
"""
return start_year, end_year
start,end = yearly_data_arg_test (surveys_df, 1988, 1993)
print('Both optional arguments:\t', start, end)
start,end = yearly_data_arg_test (surveys_df)
print('Default values:\t\t\t', start, end)SALIDA
Both optional arguments: 1988 1993
Default values: 1977 2002Los “\t” en print son tabulaciones, y son usadas para
alinear el texto y facilitar la lectura.
Pero ¿qué sucede si nuestro dataset no comienza en 1977 ni termina en 2002? Podemos modificar la función de tal forma que ella misma mire cuál es el primer y cuál es el último año si estos argumentos no son provistos por el usuario:
PYTHON
def yearly_data_arg_test(all_data, start_year = None, end_year = None):
"""
Modificación de yearly_data_csv_writer para probar argumentos con valores
por defecto!
start_year --- el primer año de datos que queremos --- por defecto: None - revisar all_data
end_year --- el último año de datos que queremos --- por defecto: None - revisar all_data
all_data --- DataFrame con datos de varios años
"""
if start_year is None:
start_year = min(all_data.year)
if end_year is None:
end_year = max(all_data.year)
return start_year, end_year
start,end = yearly_data_arg_test (surveys_df, 1988, 1993)
print('Both optional arguments:\t', start, end)
start,end = yearly_data_arg_test (surveys_df)
print('Default values:\t\t\t', start, end)SALIDA
Both optional arguments: 1988 1993
Default values: 1977 2002Ahora los valores por defecto de los argumentos
start_year y end_year en la función
yearly_data_arg_test son None. Esta es una
constante incorporada en Python que indica la ausencia de un valor -
esencialmente indica que la variable existe en el directorio de nombres
de variables (el namespace) de la función pero que no
corresponde a ningún objeto existente.
Challenge - Variables
¿Qué tipo de objeto corresponde a una variable declarada como
None? (Pista: crea una variable con el valorNoney usa la funcióntype())Compara el comportamiento de la función
yearly_data_arg_testcuando los argumentos tienenNonecomo valor por defecto y cuando no tienen valores por defecto.¿Qué ocurre si solo incluimos un valor para
start_yearal llamar a la función?, ¿puedes escribir una llamada a la función con solo un valor paraend_year? (Pista: piensa en cómo la función debe estar asignándole valores a cada uno de sus argumentos - ¡esto está relacionado con la necesidad de poner los argumentos que no tienen valores por defecto antes de los que sí tienen valores por defecto en la definición de la función!)
Sentencias if
El cuerpo de la función anterior ahora tiene dos condicionales
if que revisan los valores de start_year y
end_year. Los condicionales if ejecutan un segmento de
código si una condición dada es cierta. Usualmente lucen así:
PYTHON
a = 5
if a<0: # ¿es cierta esta primera condición?
# si a ES menor que cero
print('a is a negative number')
elif a>0: # La primera condición no es cierta, ¿la segunda?
# si a NO ES menor que cero y ES mayor que cero
print('a is a positive number')
else: # No se cumplieron las dos condiciones
# si a NO ES menor que cero y NO ES mayor que cero
print('a must be zero!')lo cual retornaría:
SALIDA
a is a positive numberCambia los valores de a para ver cómo funciona este
código. La palabra clave elif significa “sino” (en inglés,
“else if”), y todos los condicionales deben terminar con un dos
puntos.
Los condicionales if en la función yearly_data_arg_test
verifican si hay algún objeto asociado a los nombres
start_year y end_year. Si estas variables son
None, los condicionales if retornan el booleano
True y ejecutan cualquier cosa que esté en su cuerpo. Por
otra parte, si los nombres están asociados a algún valor (es decir,
recibieron un número al ser llamada la función), los condicionales if
retornarán False y no ejecutan su cuerpo. El condicional
opuesto, que retornaría True si las variables estuvieran
asociadas con objetos (es decir, si hubieran recibido valores al
llamarse la función), sería if start_year y
if end_year.
Tal y como la hemos escrito hasta este momento, la función
yearly_data_arg_test asocia los valores que le pasamos
cuando la llamamos con los argumentos en la definición de la función
solo basados en su orden. Si la función recibe solo dos valores al ser
llamada, el primero será asociado con all_data y el segundo
con start_year, sin importar cuál era nuestra intención.
Podemos solucionar este problema al llamar la función usando argumentos
keyword, en donde cada uno de los argumentos en la
definición de la función está asociado con una keyword
y al llamar la función pasamos valores a los parámetros usando estas
keywords:
PYTHON
start,end = yearly_data_arg_test (surveys_df)
print('Default values:\t\t\t', start, end)
start,end = yearly_data_arg_test (surveys_df, 1988, 1993)
print('No keywords:\t\t\t', start, end)
start,end = yearly_data_arg_test (surveys_df, start_year = 1988, end_year = 1993)
print('Both keywords, in order:\t', start, end)
start,end = yearly_data_arg_test (surveys_df, end_year = 1993, start_year = 1988)
print('Both keywords, flipped:\t\t', start, end)
start,end = yearly_data_arg_test (surveys_df, start_year = 1988)
print('One keyword, default end:\t', start, end)
start,end = yearly_data_arg_test (surveys_df, end_year = 1993)
print('One keyword, default start:\t', start, end)SALIDA
Default values: 1977 2002
No keywords: 1988 1993
Both keywords, in order: 1988 1993
Both keywords, flipped: 1988 1993
One keyword, default end: 1988 2002
One keyword, default start: 1977 1993Desafío - Modificando funciones
Reescribe las funciones
one_year_csv_writeryyearly_data_csv_writerpara que tengan argumentos keyword con valores por defecto.Modifica las funciones de tal forma que no creen archivos para un año si éste no está en los datos y que muestre una alerta al usuario (Pista: usa condicionales para esto. Si quieres un reto más, ¡usa
try!)Este código verifica si un directorio existe, sino lo crea. Añade un poco de código a la función que escribe los archivos CSV para verificar si existe el directorio al que piensas escribir.
PYTHON
if 'dir_name_here' in os.listdir('.'):
print('Processed directory exists')
else:
os.mkdir('dir_name_here')
print('Processed directory created')- El código que has escrito hasta este momento usando el bucle
for está bastante bien, pero no necesariamente es
reproducible con datasets diferentes. Por ejemplo, ¿qué
pasa con el código si tenemos datos para más años? Usando las
herramientas que aprendiste en las actividades anteriores, crea una
lista de todos los años representados en los datos. Después crea un
bucle para procesar tu información, comenzando desde el primer año y
terminando en el último usando la lista. (Pista: puedes crear un bucle
con la lista así:
for years in year_list:)
- Los bucles nos permiten repetir una serie de acciones un número dado de veces o mientras una condición es cierta.
- Podemos automatizar tareas que se deben repetir un número
predefinido de veces utilizando bucles
for. - Una tarea de automatización típica en programación es generar secuencias de archivos con nombres distinos que siguen un patrón, esto se puede realizar fácilmente manipulando cadenas de caracteres con el nombre de los archivos dentro de bucles de repetición a medida que se van creando.
- Es conveniente definir funciones para establecer bloques de código reutilizables. Las funciones se pueden diseñar para que acepten argumentos de entradas para generalizar su funcionalidad y devolver distintos tipos de resultados.
- Las sentencias
ifpermiten elegir cuales bloques de código ejecutar según según se cumplan o no distintas condiciones.
Content from Creando gráficos con plotnine
Última actualización: 2023-02-07 | Mejora esta página
Nota
Hoja de ruta
Preguntas
- ¿Cómo puedo visualizar datos en Python?
- ¿Qué es la ‘gramática de gráficos’?
Objetivos
- Crear un objeto
plotnine. - Establecer configuraciones para gráficos.
- Modificar un objeto
plotnineexistente. - Cambiar la estética de un gráfico, como el color.
- Editar las etiquetas de los ejes.
- Construir gráficos complejos paso a paso.
- Crear gráficos de dispersión, gráficos de caja y gráficos de series.
- Usar los comandos
facet_wrapyfacet_gridpara crear una colección de gráficos que dividen los datos por una variable categórica. - Crear estilos personalizados para tus gráficos.
Python tiene muy buenos recursos para crear gráficos incorporados en
el paquete matplotlib, pero para éste episodio,
utilizaremos el paquete [plotnine] (https://plotnine.readthedocs.io/en/stable/),
que facilita la creación de gráficos informativos usando datos
estructurados. El paquete plotnine está basado en la
implementación R de ggplot2 y La
gramática de gráficos por Leland Wilkinson. Además el paquete plotnine
está construido sobre matplotlib e interactúa bien con
Pandas.
Al igual que con los otros paquetes, plotnine necesita
ser importado. Es bueno practicar usando una abreviatura como usamos
pd para Pandas:
Desde ahora todas las funciones de plotnine se pueden
acceder usando p9. por delante.
Para los ejercicios usaremos los datos de surveys.csv
descartando los valores NA.
Creando gráficos con plotnine
El paquete plotnine (es parte de La
gramática de gráficos) se usa para la creación de gráficos complejos
a partir de los datos en un DataFrame. Utiliza
configuraciones por defecto que ayudan a crear gráficos con calidad de
publicación con unos pocos ajustes.
Los gráficos plotnine se construyen paso a paso
agregando nuevos elementos uno encima del otro usando el operador
+. Poniendo cada paso entre paréntesis ()
proporciona una sintaxis compatible con Python.
Para construir un gráfico plotnine necesitamos:
- Conectar el gráfico a un
DataFrameespecífico usando el argumentodata:
Como no hemos definido nada más, sólo se presenta un marco vacío para el gráfico.
- Define las opciones del gráfico usando
mappingy estéticasaes, para seleccionar las variables que quieres mostrar en el gráfico, y definir la presentación de estas variables, como tamaño, color, forma, etc. Las ésteticas más importantes son:x,y,alpha,colorocolour,fill,linetype,shape,sizeystroke.
- Todavía no tenemos un gráfico, primero tenemos que definir qué tipo
de geometría utilizar. Puedes interpretar ésto como: las variables que
se usan en el gráfico son las que serán modificadas por objetos o
geometrías. Lo más sencillo es probablemente usar puntos.
geom_pointes una de las opciones de geometríageoms, que define la representación gráfica de los datos. Otras geometrías songeom_line,geom_bar, etc. Para agregar ungeomal gráfico usa el símbolo+:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
+ p9.geom_point()
)El símbolo + en el paquete plotnine es
particularmente útil porque te permite modificar los objetos
plotnine existentes. Esto significa que puedes configurar
fácilmente el gráfico con plantillas y explorar
convenientemente diferentes tipos de gráficos. El gráfico anterior
también se puede generar con código como este:
PYTHON
# Crea un marco para el gráfico definiendo las variables
surveys_plot = p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
# Dibuja los puntos en el marco
surveys_plot + p9.geom_point()
Desafío - gráfico de barras
Trabajando con los datos de survey_complete, usa la
columna plot-id para crear un gráfico de barras
geom_bar que cuente el número de registros para cada
parcela. (Mira la documentación de la geometría de barras para manejar
los conteos).
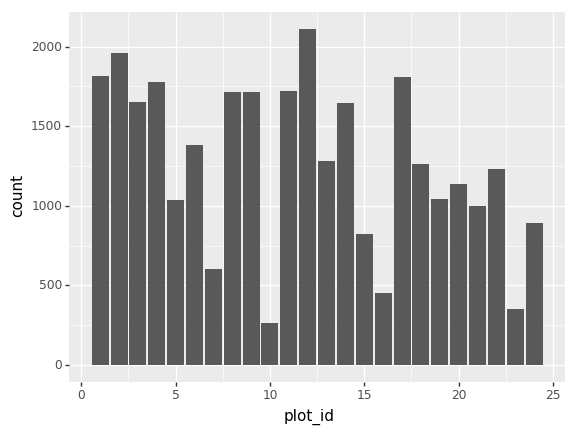
Notas:
- Cualquier ajuste en la función
ggplot()se visualiza en las capas del gráfico (por ejemplo, las configuraciones universales). Esto incluye los ejesxyyque configuraste en las capa de estéticasaes(). - También puedes especificar estéticas individuales para cada
geomindependientemente de las estéticas definidas globalmente en la funciónggplot().
Construyendo tus gráficos de forma iterativa
La construcción de gráficos con plotnine es típicamente
un proceso iterativo. Empezamos definiendo el conjunto de datos que
usaremos, colocaremos los ejes y elegiremos una geometría. Por lo tanto,
los elementos mínimos de cualquier gráfico son
data,aes y geom-*:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
+ p9.geom_point()
)Luego, comenzamos a modificar este gráfico para extraer más
información. Por ejemplo, podemos agregar transparencia
(alfa) para evitar la obstrucción visual por aglomeración
de puntos:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
+ p9.geom_point(alpha=0.1)
)
¡También puedes agregar color a los puntos!
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
+ p9.geom_point(alpha=0.1, color='blue')
)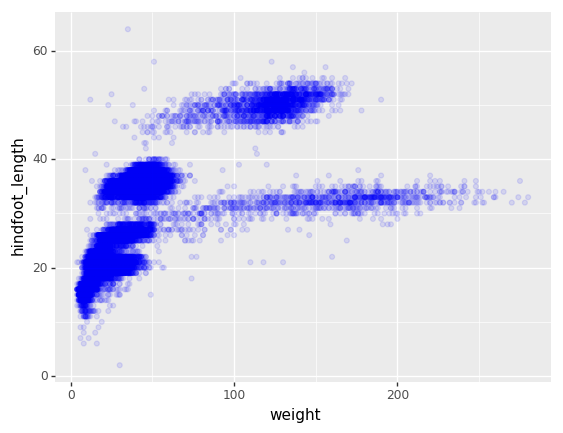
Si quieres usar un color diferente para cada especie, tienes que
conectar la columna species_id con la estética del
color:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight',
y='hindfoot_length',
color='species_id'))
+ p9.geom_point(alpha=0.1)
)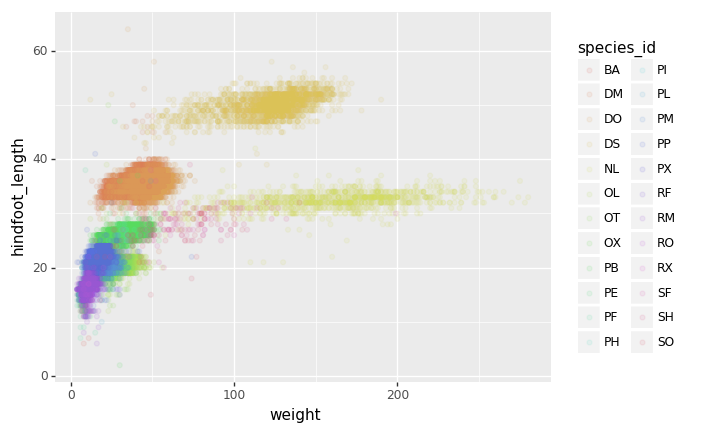
Aparte de las configuraciones en los argumentos data,
aes y los elementos geom-*, también se pueden
agregar elementos adicionales, usando el signo +:
- Cambiando las etiquetas:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length', color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.xlab("Weight (g)")
)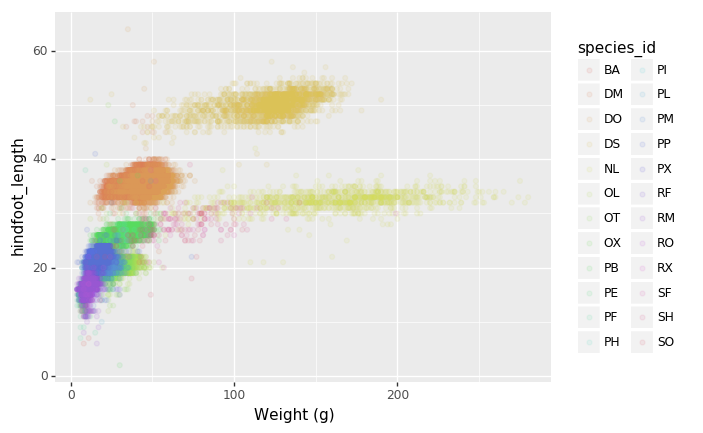
- Puedes también cambiar las escalas para colores, ejes…. Por ejemplo, una versión del gráfico anterior usando el logarítmo de los números en el eje x podría ayudar a una mejor interpretación de los números más pequeños:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length', color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.xlab("Weight (g)")
+ p9.scale_x_log10()
)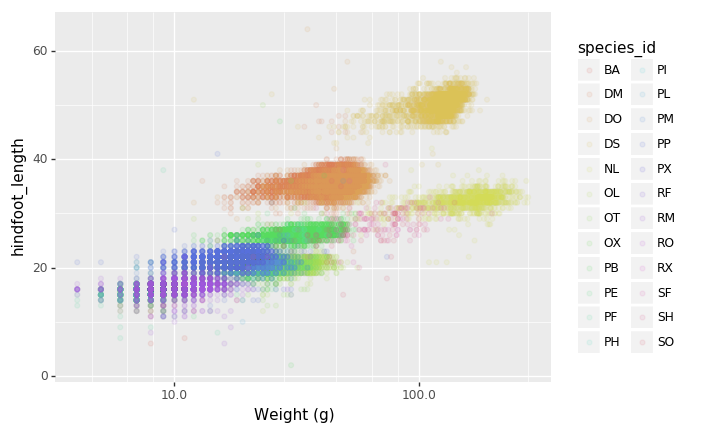
- También puedes escoger un tema (
theme_*) o algunos elementos específicos del tema (theme). Por lo general, los gráficos con fondo blanco parecen más legibles cuando se imprimen. Entonces, podemos configurar el fondo a blanco usando la funcióntheme_bw()y cambiar el tamaño del texto contheme().
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length', color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.xlab("Weight (g)")
+ p9.scale_x_log10()
+ p9.theme_bw()
+ p9.theme(text=p9.element_text(size=16))
)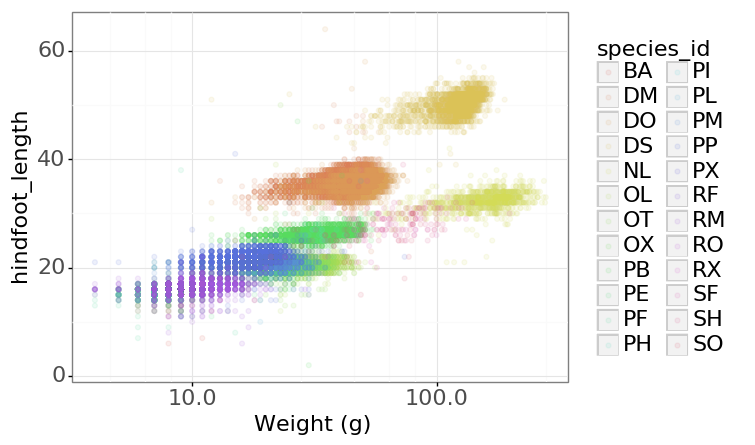
Desafío - retocando un gráfico de barras
Usa el código del ejercicio anterior y cambia la estética de color
por la variable sex, también cambia la geometría para tener
un gráfico de barras, finalmente, cambia la escala scale
del color de relleno para que tengas una barra azul y una naranja usando
blue y orange (mira este link en inglés de la
referencia API
reference plotnine para encontrar la función que necesitas).

Gráficos de distribuciones
Visualizar una distribución de datos es una tarea común en el
análisis y exploración de datos. Por ejemplo, para visualizar la
distribución de datos de la columna weight por cada especie
species_id, puedes usar una gráfica de caja:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='species_id',
y='weight'))
+ p9.geom_boxplot()
)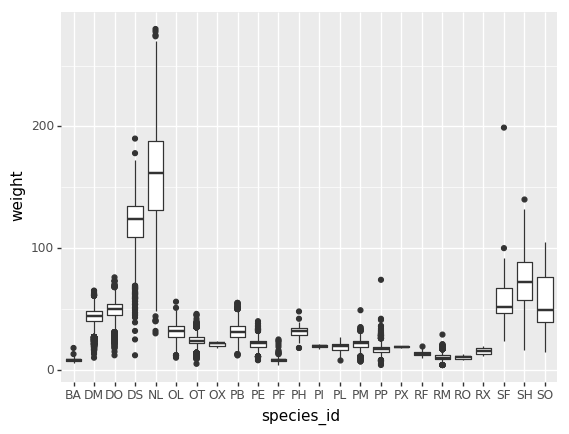
Agregando los puntos a la gráfica de caja nos dá una mejor idea de la distribución de las observaciones:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='species_id',
y='weight'))
+ p9.geom_jitter(alpha=0.2)
+ p9.geom_boxplot(alpha=0.)
)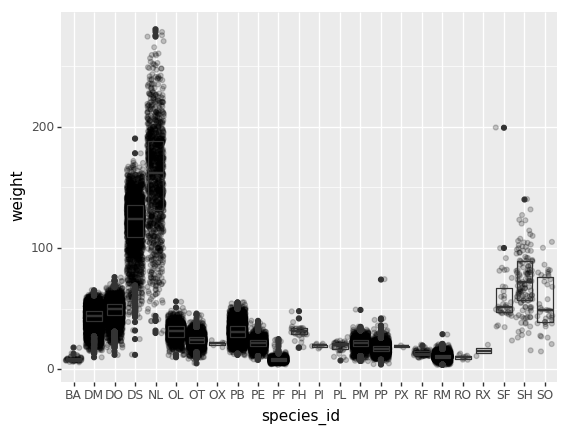
Desafío - distribuciones
Los gráficos de caja son resúmenes útiles, pero ocultan la forma de la distribución. Por ejemplo, si hay una distribución bimodal, esto no se observaría con un gráfico de caja. Una alternativa al gráfico de caja es el gráfico de violín, donde se dibuja la forma (de la densidad de los puntos).
Al visualizar datos, es importante considerar la escala de la observaciones. Por ejemplo, puede valer la pena cambiar la escala del eje para distribuir mejor las observaciones en el espacio.
- Reemplaza el gráfico de caja con uno de violín, mira
geom_violin() - Transforma la columna
weighta la escala log10, mirascale_y_log10() - Agrega color a los puntos en tu gráfico de acuerdo a la parcela
donde la muestra fue tomada (
plot_id).
Sugerencia: Primero comprueba la clase de plot_id. Si
usas factor() dentro de la estética aes,
plotnine manejará los valores como categorías.
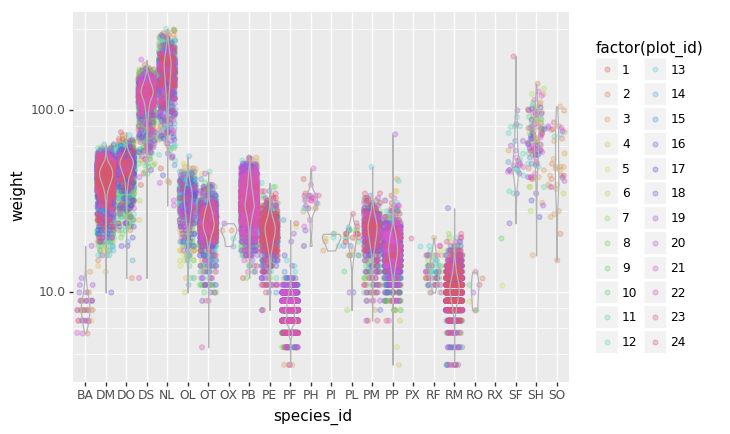
Gráficos de series
Calculemos el número de cada tipo de especie por año. Para esto
primero tenemos que agrupar las especies (species_id) por
cada año year.
PYTHON
yearly_counts = surveys_complete.groupby(['year', 'species_id'])['species_id'].count()
yearly_countsCuando revisamos los resultados del cálculo anterior, vemos que
year y species_id son índices de filas.
Podemos cambiar este indice para que sean usados como una variable de
columnas:
Los gráficos de series se pueden visualizar usando líneas
(geom_line) con años en el eje x y el conteo
en el eje y.
Desafortunadamente eso no funciona, porque nos muestra todas las
especies juntas. Tenemos que especificar que queremos una línea para
cada especie. Esto se modifica en la función de estética conectando el
color con la variable species_id:
PYTHON
(p9.ggplot(data=yearly_counts,
mapping=p9.aes(x='year',
y='counts',
color='species_id'))
+ p9.geom_line()
)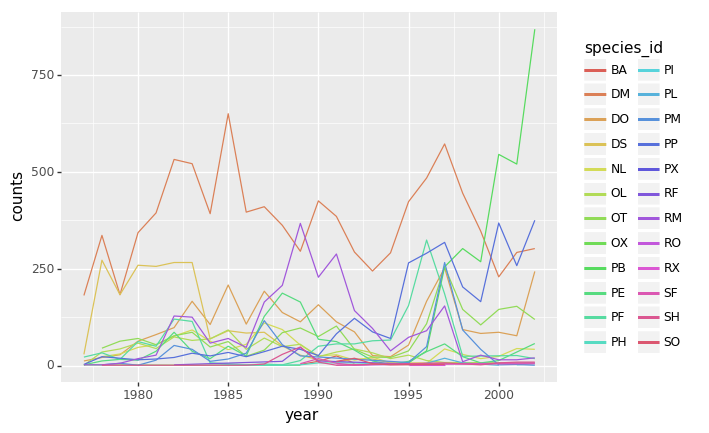
Facetas
Como cualquier biblioteca que maneje la gramática de gráficos,
plotnine tiene una técnica especial denominada
faceting que permite dividir el gráfico en múltiples gráficos
en función de una categoría incluida en el conjunto de datos.
¿Recuerdas el gráfico de puntos que creaste antes, usando
weight y hindfoot_length?
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight',
y='hindfoot_length',
color='species_id'))
+ p9.geom_point(alpha=0.1)
)Podemos reusar este mismo código y agregar una faceta con
facet_wrap en base a una categoría para dividir el gráfico
para cada uno de los grupos, por ejemplo, usando la variable
sex:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight',
y='hindfoot_length',
color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.facet_wrap("sex")
)
Ahora podemos aplicar el mismo concepto con cualquier categoría:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight',
y='hindfoot_length',
color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.facet_wrap("plot_id")
)
La capa de facetas facet_wrap divide los gráficos
arbitrariamente para que entren sin problemas en una hoja. Por otro lado
si quieres definir explícitamente la distribución de los gráficos usa
facet_grid con una fórmula (rows ~ columns) un
punto . indica que es sólo una fila o una columna.
PYTHON
# Selecciona unos años que te interesen
survey_2000 = surveys_complete[surveys_complete["year"].isin([2000, 2001])]
(p9.ggplot(data=survey_2000,
mapping=p9.aes(x='weight',
y='hindfoot_length',
color='species_id'))
+ p9.geom_point(alpha=0.1)
+ p9.facet_grid("year ~ sex")
)
Desafío - facetas 1
Crea un gráfico separado por cada especie, que muestre como el peso medio de las especies cambia por año.
Desafío - facetas 2
Usando el código del ejercicio anterior, compara visualmente como los
pesos de machos y hembras van cambiando en el tiempo. Crea un gráfico
separado por cada sex que use un color diferente por cada
especie species_id.
yearly_weight = surveys_complete.groupby([‘year’, ‘species_id’, ‘sex’])[‘weight’].mean().reset_index()
(p9.ggplot(data=yearly_weight, mapping=p9.aes(x=‘year’, y=‘weight’, color=‘species_id’)) + p9.geom_line() + p9.facet_wrap(“sex”) ) {: .language-python}
Más retoques
Como la sintaxis de plotnine sigue la versión original
del paquete de R ggplot2, la documentación de
ggplot2 te dá mas información e inspiración para retocar
tus gráficos. Mira la hoja resumen de ggplot2 cheat
sheet, y piensa de que maneras puedes mejorar el gráfico. Puedes
escribir tus ideas y comentarios en el Etherpad.
Las opciones temáticas nos proveen una gran variedad de adaptaciones visuales. Usa el siguiente ejemplo de un gráfico de barras que presenta las observaciones por año.
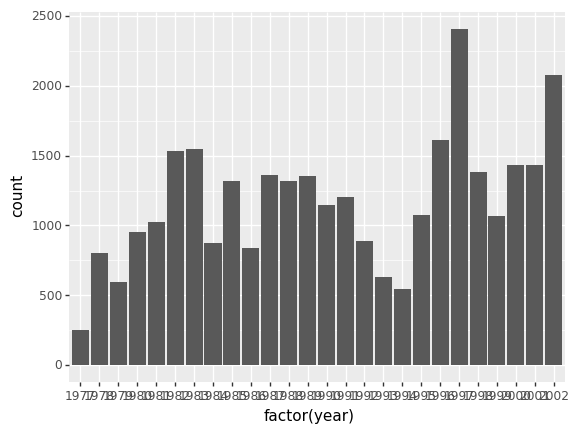
Aquí hemos usado el año year como una categoría usando
la función factor. Pero al hacer esto, las etiquetas de los
años se sobreponen. Usando una opción theme podemos rotar
las etiquetas en el eje x:
PYTHON
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='factor(year)'))
+ p9.geom_bar()
+ p9.theme_bw()
+ p9.theme(axis_text_x = p9.element_text(angle=90))
)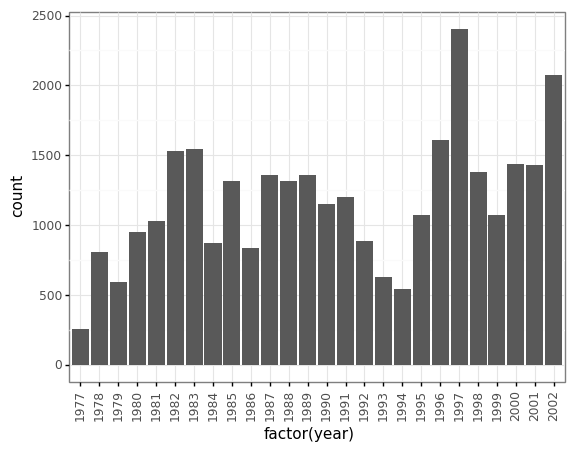
Cuando encuentres las opciones de visualización que te agraden y forman parte del tema, puedes guardar estas opciones en un objeto para luego reusarlo en los próximos gráficos que vayas a crear.
PYTHON
my_custom_theme = p9.theme(axis_text_x = p9.element_text(color='grey', size=10,
angle=90, hjust=.5),
axis_text_y = p9.element_text(color='grey', size=10))
(p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='factor(year)'))
+ p9.geom_bar()
+ my_custom_theme
)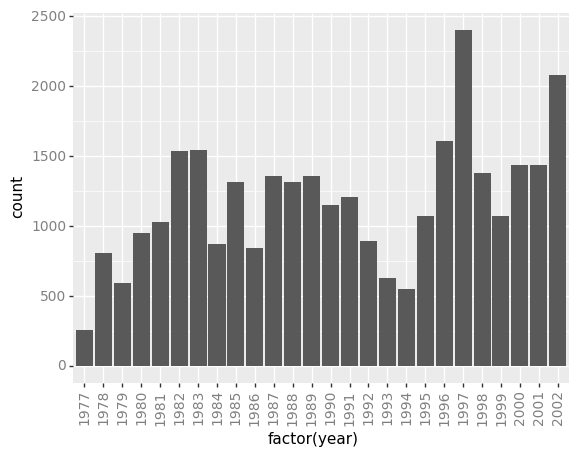
Desafío - hecho a medida
Tómate otros cinco minutos para mejorar uno de los gráficos anteriores, o crea un nuevo gráfico hecho a medida, con los retoques que quieras.
Challenge
Aquí hay algunas ideas:
- Intenta cambiar el grosor de las lineas en el gráfico de línea.
- ¿Podrías cambiar la leyenda y sus etiquetas?
- Usa una paleta de colores nueva (mira las opciones aquí http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/)
Después de crear tu nuevo gráfico, puedes guardarlo en diferentes
formatos. También puedes cambiar las dimensiones, la resolución usando
width, height and dpi:
PYTHON
my_plot = (p9.ggplot(data=surveys_complete,
mapping=p9.aes(x='weight', y='hindfoot_length'))
+ p9.geom_point()
)
my_plot.save("scatterplot.png", width=10, height=10, dpi=300)- Las variables
data,aesygeometryson los elementos principales de un gráfico deplotnine. - Con el operador
+, se agregan elementos adicionales al gráfico, por ejemploscale_*,theme_*,xlab,ylabyfacet_*.
Content from Entrada de datos y visualización - Matplotlib y Pandas
Última actualización: 2023-02-07 | Mejora esta página
Resumiendo
Hoja de ruta
Preguntas
- ¿Qué otras herramientas aparte de ggplot puedo usar para crear gráficos?
- ¿Por qué usar Python para crear gráficos?
Objetivos
- Importar herramientas de pyplot para crear figuras en Python.
- Usar matplotlib para ajustar objetos de Pandas o plotnine.
Hasta aquí, hemos repasado las tareas que se suelen llevar a cabo en el manejo y procesamiento de datos utilizando los archivos limpios que hemos proporcionado en el taller. En este ejercicio de repaso final, realizaremos muchas de las tareas que hemos visto pero con datasets reales. Esta lección también incluye visualización de datos.
A diferencia de las anteriores, en esta lección no se dan instrucciones paso a paso para realizar cada una de las tareas. Usa los materiales de las lecciones que ya has estudiado, así como la documentación de Python.
Obtener datos
Hay muchos repositorios en línea desde los cuales puedes obtener datos. Te proporcionamos un archivo de datos para usar con estos ejercicios, pero no dudes en utilizar cualquier conjunto de datos que encuentres relevante para tu investigación. El archivo [bouldercreek_09_2013.txt contiene datos sobre vertidos de agua, resumidos en 15 intervalos de 15 minutos (en pies cúbicos por segundo de una estación hidrométrica en Boulder Creek en North 75th Street (USGS gage06730200 durante el periodo 1-30 de Septiembre de 2013. Si deseas usar este dataset, lo encontrarás en la carpeta de datos.
Limpia tus datos y ábrelos con Python y Pandas
Para empezar, importa tu archivo de datos a Python usando Pandas. ¿No te funcionó? Puede que tu archivo de datos tenga un encabezado que Pandas no reconozca como parte de la tabla. Elimina este encabezado, ¡pero no lo hagas borrándolo en un editor de texto! Usa la terminal o Python para hacerlo; no quisieras tener que hacer esto a mano si tuvieras muchos archivos por procesar.
Si aún tienes problemas para importar los datos como una tabla con Pandas, consulta la documentación. Prueba a abrir la docstring en un ipython notebook utilizando un signo de interrogación. Por ejemplo:
Fíjate en los argumentos de la función para ver si hay un valor
predeterminado que sea diferente al que requiere tu archivo (Sugerencia:
probablemente el problema sea el delimitador o separador. Los
delimitadores más comunes son ',' comas, ' '
espacios, y '\t' tabulaciones).
Crea un DataFrame que incluya sólo los valores de los datos que te sean útiles. En nuestro archivo de ejemplo de la estación hidrométrica, esos valores podrían ser la fecha, la hora y las mediciones de descarga o vertido. Convierte cualquier medida de unidades imperiales a unidades SI. También puedes cambiar el nombre de las columnas en el DataFrame del siguiente modo:
PYTHON
df = pd.DataFrame({'1stcolumn':[100,200], '2ndcolumn':[10,20]}) # esto crea un __DataFrame__ para el ejemplo!
print('With the old column names:\n') # El \n crea una nueva línea, para que sea más fácil de ver
print(df)
df.columns = ['FirstColumn','SecondColumn'] # renombra las columna!
print('\n\nWith the new column names:\n')
print(df)SALIDA
Con los nombres antiguos de las columnas:
1stcolumn 2ndcolumn
0 100 10
1 200 20
Con los nuevos nombres de columna:
FirstColumn SecondColumn
0 100 10
1 200 20El paquete Matplotlib
Matplotlib es un paquete de Python usado ampliamente por la comunidad científica de Python para crear gráficos de alta calidad, listos para publicar. Admite una amplia gama de formatos de gráficos rasterizados y vectoriales, tales como PNG, PostScript, EPS, PDF y SVG.
Además, Matplotlib es el motor que hay detrás de las capacidades
gráficas de los paquetes Pandas y plotnine. Por ejemplo, cuando
invocamos el método .plot en objetos de datos Pandas, de
hecho estamos usando el paquete matplotlib.
Primero, importamos la caja de herramientas pyplot:
¡Ahora leemos los datos y los representarlos en un gráfico!
PYTHON
surveys = pd.read_csv("data/surveys.csv")
my_plot = surveys.plot("hindfoot_length", "weight", kind="scatter")
plt.show() # no necesariamente en Jupyter Notebooks
El objeto que obtenemos es un objeto matplotlib (puedes verificarlo
tu mismo con type(my_plot)), al que podemos ajustarle y
realizarle mejoras adicionales utilizando otros métodos de
matplotlib.
Sugerencia
Matplotlib en sí mismo puede resultar algo abrumador, por lo que una estrategia útil de entrada es hacer todo lo posible en capas de conveniencia, p.e. empezar creando los gráficos en Pandas o plotnine y luego usar matplotlib para el resto.
En esta lección cubriremos algunos comandos básicos para crear y formatear gráficos con matplotlib. Un gran recurso para ayudarnos a crear y agregar estilo a nuestras figuras es la galería matplotlib (http://matplotlib.org/gallery.html), la cual incluye gráficos en todo tipo de estilos junto con el código fuente para crearlos.
plt pyplot vs matplotlib basado en objetos
Matplotlib se integra bien con el paquete NumPy y permite usar arrays de NumPy como entrada para las funciones para crear gráficos disponibles. Considera los siguientes datos de ejemplo, creados con NumPy extrayendo 1000 muestras de una distribución normal con un valor medio de 0 y una desviación estándar de 0.1:
Para representar un histograma de la distribución normal, podemos
usar la función hist directamente:
Sugerencia: Visualization multiplataforma de Figuras
Los Jupyter Notebooks nos simplifican muchos
aspectos de nuestro análisis y de las visualizaciones. Por ejemplo,
hacen buena parte del trabajo de visualización por nosotros. Pero quizás
no todos tus colaboradores trabajan con Jupyter
Notebooks. El comando .show() te permite
visualizar los gráficos tanto si trabajas en la línea de comandos, con
un script o en el intérprete de IPython. En el ejemplo
anterior, si añades plt.show() después de crear el gráfico,
eso permitirá que tus colegas que no estén usando Jupyter
notebooks puedan reproducir igualmente tu trabajo en su
plataforma.
o creas primero los objetos figure y axis
de matplotlib y luego agregas un histograma con 30 contenedores de
datos:
PYTHON
fig, ax = plt.subplots() # initiate an empty figure and axis matplotlib object
ax.hist(sample_data, 30)Aunque el último enfoque requiere un poco más de código para crear la misma trama, la ventaja es que nos da control total sobre el gráfico y podemos agregarle nuevos elementos tales como etiquetas, una cuadrícula, títulos u otros elementos visuales. Por ejemplo, podemos agregar ejes adicionales a la figura y personalizar sus etiquetas:
PYTHON
fig, ax1 = plt.subplots() # preparar un gráfico con matplotlib
ax1.hist(sample_data, 30)
# Crear el gráfico de una distribución Beta
a = 5
b = 10
beta_draws = np.random.beta(a, b)
# editar las etiquetas
ax1.set_ylabel('density')
ax1.set_xlabel('value')
# añadir ejes adicionales a la figura
ax2 = fig.add_axes([0.125, 0.575, 0.3, 0.3])
#ax2 = fig.add_axes([left, bottom, right, top])
ax2.hist(beta_draws)
Reto - Dibujo a partir de distribuciones
Echa un vistazo a la documentación aleatoria deNumPy https://docs.scipy.org/doc/numpy-1.14.0/reference/routines.random.html. Toma una distribución con la que no tengas ninguna familiaridad e intenta muestrearla y visualizarla.
Enlaza matplotlib, Pandas y plotnine
Cuando creamos un gráfico usando pandas o plotnine, ambas bibliotecas usan matplotlib para crear esas. The plots created in pandas or plotnine are matplotlib objects, which enables us to use some of the advanced plotting options available in the matplotlib library. Because the objects output by pandas and plotnine can be read by matplotlib, we have many more options than any one library can provide, offering a consistent environment to make publication-quality visualizations.
PYTHON
fig, ax1 = plt.subplots() # prepara un gráfico de matplotlib
surveys.plot("hindfoot_length", "weight", kind="scatter", ax=ax1)
# realiza ajustes al gráfico con matplotlib:
ax1.set_xlabel("Hindfoot length")
ax1.tick_params(labelsize=16, pad=8)
fig.suptitle('Scatter plot of weight versus hindfoot length', fontsize=15)
Para recuperar una figura de matplotlib de plotnine para luego
ajustarla, usa la función draw() en plotnine:
PYTHON
import plotnine as p9
myplot = (p9.ggplot(data=surveys,
mapping=p9.aes(x='hindfoot_length', y='weight')) +
p9.geom_point())
# convierte el output de plotnine a un objeto de matplotlib
my_plt_version = myplot.draw()
# Realiza más ajustes al gráfico con matplotlib:
p9_ax = my_plt_version.axes[0] # cada subgráfico es un ítem en una lista
p9_ax.set_xlabel("Hindfoot length")
p9_ax.tick_params(labelsize=16, pad=8)
p9_ax.set_title('Scatter plot of weight versus hindfoot length', fontsize=15)
plt.show() # esto no es necesario en Jupyter Notebooks
Reto - Pandas y matplotlib
Carga el conjunto de datos de streamgage con Pandas, haz un subconjunto filtrando la semana de la inundación de Front Range en 2013 (del 11 al 15 de septiembre) y crea un hidrograma (gráfico de líneas) usando Pandas, vinculándolo a un objeto de maptlotlib
axvacío . Crea un segundo eje que muestre el conjunto de datos entero. Adapta el título y las etiquetas de los ejes usando matplotlib.Respuestas
discharge = pd.read_csv("data/bouldercreek_09_2013.txt", skiprows=27, delimiter="\t", names=["agency", "site_id", "datetime", "timezone", "discharge", "discharge_cd"]) discharge["datetime"] = pd.to_datetime(discharge["datetime"]) front_range = discharge[(discharge["datetime"] >= "2013-09-09") & (discharge["datetime"] < "2013-09-15")] fig, ax = plt.subplots() front_range.plot(x ="datetime", y="discharge", ax=ax) ax.set_xlabel("") # no label ax.set_ylabel("Discharge, cubic feet per second") ax.set_title(" Front Range flood event 2013") discharge = pd.read_csv("../data/bouldercreek_09_2013.txt", skiprows=27, delimiter="\t", names=["agency", "site_id", "datetime", "timezone", "flow_rate", "height"]) fig, ax = plt.subplots() flood = discharge[(discharge["datetime"] >= "2013-09-11") &
(discharge["datetime"] < "2013-09-15")]ax2 = fig.add_axes([0.65, 0.575, 0.25, 0.3]) flood.plot(x =“datetime”, y=“flow_rate”, ax=ax) discharge.plot(x =“datetime”, y=“flow_rate”, ax=ax2) ax2.legend().set_visible(False)
Challenge
ax.set_xlabel(““) # no label ax.set_ylabel(”Discharge, cubic feet per second”) ax.legend().set_visible(False) ax.set_title(” Front Range flood event 2013”)
{: .language-python}
Guardar figuras de matplotlib
Una vez que estés satisfecho con el gráfico resultante, puedes
guardar el gráfico con el método .savefig(*args) de
matplotlib:
Lo cual guardará la fig creada usando Pandas /
matplotlib como un archivo png con nombre my_plot_name
Matplotlib reconoce la extensión usada en el nombre del archivo y soporta (en la mayoría de computadoras) los formatos png, pdf, ps, eps y svg.Reto - Guardar figuras a un archivo
Repasa la documentación del método savefig y comprueba
cómo cumplir con los requerimientos de las revistas que aceptan archivos
en pdf con dpi >= 300.
Crea otros tipos de gráficos:
Matplotlib permite crear muchos otros tipos de gráficos del mismo
modo como hace gráficos de líneas bidimensionales. Mira los ejemplos en
http://matplotlib.org/users/screenshots.html
e intenta realizar alguno de ellos (Haz click en el enlace “Source code”
y haz copy y paste en una nueva celda en ipython notebook o bien
guárdalo como un archivo de texto con extensión .py y
ejecútalo en la línea de comandos).
Reto - Gráfico final
Muestra tus datos usando uno o más gráficos de entre los mostrados en la galería de ejemplos. Las que elijas dependerán del contenido de tu propio archivo de datos. Si está usando el archivo [bouldercreek_09_2013.txt, podrías por ejemplo, hacer un histograma de la cantidad de días con un vertido medio determinado, usar gráficos de barras para mostrar estadísticas de vertido diarias o explorar las diferentes formas en que matplotlib puede manejar fechas y horas.
- Matplotlib es el motor detrás de los gráficos creados con plotnine y Pandas.
- La filosofía de los gráficos de matplotlib, basada en objetos, permite la personalización detallada de los gráficos una vez creados.
- Es posible exportar gráficos a un archivo usando el método
savefig.
Content from Acceso a base de datos SQLite usando Python y Pandas
Última actualización: 2023-02-07 | Mejora esta página
Python y SQL
Hoja de ruta
Preguntas
- ¿Cómo conectarse a una base de datos SQLite desde Python?
- ¿Cómo extraer datos de una base de datos SQLite a un DataFrame de Python?
- ¿Cuáles son los beneficios de usar una base de datos en vez de un archivo CSV?
Objetivos
- Usa el módulo sqlite3 para interactuar con una base de datos SQL.
- Accede a los datos almacenados en SQLite usando Python.
- Describe las diferencias de interactuar con datos almacenados en un archivo CSV y datos almacenados en SQLite.
- Describe los beneficios de acceso a datos usando una base de datos en comparación con un archivo CSV.
Cuando lees un archivo de datos en Python y lo asignas a una
variable, estás usando la memoria de tu computadora para guardar esta
variable. Acceder a datos almacenados en una base de datos como SQL no
solo es más eficiente, sino que también te permite extraer e importar
todo o partes del dataset que necesites.
En la siguiente lección, veremos algunos enfoques que se pueden tomar para conectarte a una base de datos, por ejemplo SQLite.
El módulo sqlite3
El módulo sqlite3
proporciona una interfaz sencilla para interactuar con bases de datos
SQLite. Primeramente, se crea un objeto de conexión usando
sqlite3.connect(), esto abre la puerta a la base de datos.
Mientras la conexión esté abierta cualquier interacción con la base de
datos requiere que crees un objeto cursor, con el comando
.cursor(). Luego el cursor estará listo para realizar todo
tipo de operaciones con el comando .execute(). Al final, no
olvides cerrar la puerta de la conexión usando el comando
.close().
PYTHON
# Importa el módulo sqlite3
import sqlite3
# Crea un objeto de conexión a la base de datos SQLite
con = sqlite3.connect("data/portal_mammals.sqlite")
# Con la conexión, crea un objeto cursor
cur = con.cursor()
# El resultado de "cursor.execute" puede ser iterado por fila
for row in cur.execute('SELECT * FROM species;'):
print(row)
# No te olvides de cerrar la conexión
con.close()Consultas
Una de las formas más comunes de interactuar con una base de datos es
haciendo consultas para extraer datos: Para seleccionar columnas del
DataFrame o tabla, usa la palabra de declaración
SELECT. Una consulta nos devuelve o retorna datos que
pueden ser una o varias filas y columnas, a este resultado también se
llama tupla. Para filtrar las tuplas basado en algún parametro, usa la
palabra WHERE. El filtro WHERE recibe
una o más condiciones.
PYTHON
# Importa el módulo sqlite3
import sqlite3
# Crea una conexión a la base de datos SQLite
con = sqlite3.connect("data/portal_mammals.sqlite")
# Con la conexión, crea un objeto cursor
cur = con.cursor()
# Ejecuta la consulta 1
cur.execute('SELECT plot_id FROM plots WHERE plot_type="Control"')
# Extrae todos los datos
cur.fetchall()
# Ejecuta la consulta 2
cur.execute('SELECT species FROM species WHERE taxa="Bird"')
# Extrae sólo el primer resultado
cur.fetchone()
# No te olvides de cerrar la conexión
con.close()Accesando datos almacenados en SQLite usando Python y Pandas
Usando Pandas, podemos importar los resultados de una consulta en SQLite a un DataFrame. Nota que puedes usar los mismos comandos o sintaxis que usamos en la lección SQLite.
Por ejemplo para usar Pandas y SQLite:
PYTHON
# Importa pandas y sqlite3
import pandas as pd
import sqlite3
# Crea una conexión a la base de datos SQLite
con = sqlite3.connect("data/portal_mammals.sqlite")
# Usa read_sql_query de pandas para extraer el resultado
# de la consulta a un DataFrame
df = pd.read_sql_query("SELECT * from surveys", con)
# Verifica que el resultado de la consulta SQL está
# almacenado en el DataFrame
print(df.head())
# No te olvides de cerrar la conexión
con.close()Almacenando datos: CSV vs SQLite
Almacenar datos en una base de datos SQLite incrementa sustancialmente el rendimiento de lectura / escritura, en comparación con archivos CSV. La diferencia en el rendimiento se hace más notable a medida que crece el tamaño del conjunto de datos (ver por ejemplo estos benchmarks).
Desafío - SQL
Crea una consulta que contenga datos de encuestas recopiladas entre 1998 y 2001 para observaciones de sexo “masculino” o “femenino” que incluyan el género y la especie de la observación, y el tipo de sitio de la muestra. ¿Cuántos registros regresa la consulta?
Crea un DataFrame (usando count) que contenga el número total de observaciones de todos los años y la suma de los pesos de observaciones de cada sitio, ordenados por el ID del sitio.
Almacenando datos: Crea nuevas tablas usando Pandas
También podemos usar pandas para crear nuevas tablas dentro de una base de datos SQLite. Aquí, volveremos a hacer un ejercicio que hicimos antes con archivos CSV usando nuestra base de datos SQLite. Primero leemos los datos de nuestra encuesta, luego seleccionamos solo los resultados de la encuesta en el año 2002 y luego los guardamos en su propia tabla para que podamos trabajar solo con ellos más adelante.
PYTHON
# Importa pandas y sqlite3
import pandas as pd
import sqlite3
# Crea una conexión a la base de datos SQLite
con = sqlite3.connect("data/portal_mammals.sqlite")
# Extrae los datos de la consulta directamente a un DataFrame
surveys_df = pd.read_sql_query("SELECT * from surveys", con)
# Selecciona sólo datos en el año 2002
surveys2002 = surveys_df[surveys_df.year == 2002]
# Escribe los datos del nuevo DataFrame en una nueva tabla en SQLite
surveys2002.to_sql("surveys2002", con, if_exists="replace")
# No te olvides de cerrar la conexión
con.close()Desafío - Guardando tus datos
Para cada uno de los desafíos del bloque anterior, modifica tu codigo para guardar los resultados en sus propias tablas en el portal de base de datos.
¿Por qué razones tú preferirías guardar los resultados de tus consultas nuevamente en la base de datos? ¿Por qué razones preferirías evitar hacer esto?
- Se puede crear una conexión con
sqlite3.connect(), y luego establecer un cursor para consultas con.cursor(). - Es posible ejecutar consultas usando
.execute(). - Puedes usar la función
.read_sql_query()de Pandas para extraer datos directamente de un DataFrame. - Se pueden escribir los datos de un DataFrame a una nueva tabla en
SQLite usando
.to_sql(). - Al final, no olvides cerrar la puerta de la conexión usando el
comando
.close().